
相关attention – 5 – GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond – 1 – 论文学习
Attention Convolutional Binary Neural Tree for Fine-Grained Visual Categorization
Abstract
由于变形、遮挡、光照等引起的类内方差高,而类间方差低,导致细粒度视觉分类(FGVC)是一项重要但具有挑战性的任务。针对弱监督FGVC的这些问题,提出了一种注意力卷积二叉神经树结构。具体来说,我们结合了沿着树结构边缘的卷积运算,并使用每个节点中的routing函数来确定树内的根到叶子的计算路径。最终的决策是根据叶节点的预测的总和来计算的。深度卷积运算学习去捕捉对象的表征,树状结构特征化从粗到细的层次特征学习过程。此外,我们使用注意力转换器模块来强制网络捕捉具有区分度的特征。在CUB-200-2011,Stanford Cars和 Aircraft数据集上的几个实验表明,我们的方法比其他最先进的方法表现还好。代码可见https://isrc.iscas.ac.cn/gitlab/research/acnet
1. Introduction
细粒度视觉分类(FGVC)旨在区分子级对象类别,如不同种类的鸟类[42,52]和花卉[1]。由于变形、遮挡和光照引起的类内视觉差异大,类间视觉差异小,使得FGVC是一项极具挑战性的任务。
近年来,卷积神经网络(CNN)由于其惊人的分类性能,在FGVC任务中占据主导地位。有些方法[29,26]侧重于提取有区分度的微妙部分,以获得准确的结果。然而,单个CNN模型难以描述从属类之间的差异(见图1)。在[34]中,针对FGVC提出了object-part注意力模型,利用对象和part的注意力去利用细微和局部的差异来区分子类别。验证了在FGVC中使用多个聚焦于不同目标区域的深度模型的有效性。

受[41]的启发,我们设计了一种用于弱监督FGVC的注意力卷积二叉神经树结构(ACNet)。它结合了沿着树结构边缘的卷积运算,并使用每个节点的routing函数来确定树内的根到叶子的计算路径作为深度神经网络。这种设计的架构使我们的方法继承了深度卷积模型的表征学习能力,以及从粗到细的层次特征学习过程。这样,树形结构中的不同分支针对不同的局部目标区域进行分类。最终的决策计算为所有叶节点预测的总和。同时,我们使用注意力转换器加强树状网络来捕获判别特征,以获得准确的结果。采用负对数似然损失,通过反向传播的随机梯度下降对整个网络进行端到端的训练。
值得注意的是,与[41]学习过程中自适应增加树结构相反,我们的方法使用预先确定深度和软决策方案的完全二叉树结构去在每个root-to-leaf路径上学习有区分度的特性,这避免了修剪误差,减少了训练时间。此外,注意力转换器模块的使用进一步帮助我们的网络实现更好的性能。在CUB-200-2011[42]、Stanford Cars[25]和Aircraft[32]数据集上进行了多次实验,结果表明,与最先进的方法相比,该方法具有良好的性能。我们还进行了消融研究,以全面了解该方法中不同组成部分的影响。
本文的主要贡献总结如下。(1)针对FGVC提出了一种新的注意力卷积二叉神经树结构。(2)引入注意力转换器,便于在树状网络中进行从粗到细的层次特征学习。(3)在三个具有挑战性的数据集(如CUB-200-2011、Stanford Cars和Aircraft)上进行的大量实验证明了我们方法的有效性。
2. Related Works
Deep supervised methods. 一些算法[51,31,18,50]使用对象注释甚至是密集的part/关键点注释来指导FGVC的深度CNN模型训练。Zhang等人[51]提出学习两个检测器,即整体对象检测器和part检测器,基于pose-normalized表征来预测细粒度类别。Liu等人[31]提出了一种全卷积注意力网络,该网络会窥探局部判别区域,以适应不同的细粒度域。[18]中的方法构建了part-stacked的CNN体系结构,通过建模目标parts的细微差异来明确解释了细粒度识别过程。在[50]中,所提出的网络由检测子网和分类子网组成。检测子网络用于生成小的语义part候选进行检测;而分类子网络可以从检测子网络检测到的parts中提取特征。然而,这些方法依赖于劳动密集型的part注释,这限制了它们在真实场景中的应用。
Deep weakly supervised method. 然而,最近的方法[52,12,38,46]只需要图像级的注释。Zheng等人[52]引入了一种多注意力CNN模型,其part生成和特征学习过程相互增强以得到准确的结果。Fu等[12]开发了一个循环注意力模块,在多个尺度上以相互增强的方式递归学习区分区域注意力和基于区域的特征表征。最近,Sun等人[38]利用每个输入图像的多个注意区域特征来调节不同输入图像之间的多个目标parts。在[46]中,通过一种新的非对称多流体系结构,学习了一组卷积滤波器来捕获特定类的判别patches。然而,上述方法只是将注意力机制整合到一个单一的网络中,影响了它们的性能。
Decision tree. 决策树是一种有效的分类算法。它根据特征的特点选择合适的方向。可解释性的内在能力使深入了解深度学习的内在机制成为有希望的方向。Xiao[48]提出了全功能神经图的原理,设计了分类任务的神经决策树模型。frost和Hinton[11]开发了一个深度神经决策树模型,以理解学习网络中特定测试用例的决策机制。Tanno等人[41]提出了自适应神经树,将表征学习融合到决策树的边缘、routing函数和叶节点中。在本文中,我们将决策树与神经网络相结合,实现了子分支选择和表征学习。
Attention mechanism. 注意机制在深度学习模仿人类视觉机制中发挥了重要作用。在[49]中,注意力被用来确保学生模型和教师模型一样集中在有区别的区域。在[21]中,我们提出了级联注意力机制来引导CNN的不同层,并将它们连接起来获得具有区分度的表征,作为最终的线性分类器的输入。Hu等人从通道的角度应用注意力机制,并根据每个通道的贡献来分配不同的权重。[47]中的CBAM模块结合了有着特征map注意力的空间区域注意力。与上述方法不同的是,我们将注意机制应用于树结构的每个分支上,以得到有区分度的区域进行分类。
3. Attention Convolutional Binary Neural Tree
我们的ACNet模型旨在将X中的每个目标样本分类到子类别中,即为X中的每个样本赋予类别标签Y,该模型包含着4个模块,有backbone网络、分支routing、注意力转换器和标签预测模块,如图2所示:

将ACNet定义为一个![]() 对,其中
对,其中![]() 表示树的拓扑,
表示树的拓扑,![]() 表示沿着
表示沿着![]() 边的操作集。我们使用完全二叉树
边的操作集。我们使用完全二叉树![]() 是结点集,n表示结点的总数,
是结点集,n表示结点的总数,![]() 是结点之间的边集,k是边的总数。因为我们使用的是完全二叉树
是结点之间的边集,k是边的总数。因为我们使用的是完全二叉树![]() ,所以n = 2h – 1,k=2h-2,其中h表示
,所以n = 2h – 1,k=2h-2,其中h表示![]() 的高度。
的高度。![]() 中的每个结点是通过一个决定样本发送路径的routing模块形成的,而注意力转换器被用作沿边的操作。
中的每个结点是通过一个决定样本发送路径的routing模块形成的,而注意力转换器被用作沿边的操作。
同时,我们在完全二叉树![]() 上使用非对称结构,即在左边使用两个注意力转换器,右边使用一个注意力转换器。这样,网络就能够捕获不同尺度的特征,用以得到准确的结果。ACNet模型的详细结构将在下面进行描述。
上使用非对称结构,即在左边使用两个注意力转换器,右边使用一个注意力转换器。这样,网络就能够捕获不同尺度的特征,用以得到准确的结果。ACNet模型的详细结构将在下面进行描述。
3.1. Architecture
Backbone network module. 由于细粒度分类中的判别区域被精准定位[46],我们需要通过限制卷积滤波器和池化核的大小和步幅来使用提取特征的一个相对较小的接受域。利用截断后的网络作为backbone网络模块提取特征,在ILSVRC CLS-LOC数据集[35]上进行预处理。与[38]类似,我们使用的输入图像大小为448×448,而不是默认的224×224。值得注意的是,ACNet也可以在其他预先训练过的网络上运行,如ResNet[15]和Inception V2[19]。在实际工作中,我们使用VGG-16[37](保留从conv1_1到conv4_3的层数)和ResNet-50[15](保留从res_1到res_4的层数)作为backbone网络。
Branch routing module. 如上所述,我们使用分支路由模块(routing module)来确定样本将被发送到哪个子节点(即左子节点或右子节点)。具体来说,如图2(b)所示,在第k层的第i个routing module ![]() 使用内核大小为1×1的一个卷积层,后面再跟着一个global context block[4]。global context block是简化后的NL block[44]和Squeeze-Excitation (SE) block [16]的改良版,其在context modeling和fusion步骤中与简化后的NL block共享相同的设置,与SE block共享transform步骤。这样,上下文信息就被合并来更好地描述目标。在这之后,使用一个global average pooling[27]、element-wise square-root和L2 normalization[28],以及一个带有sigmoid激活函数的全连接层去生成一个值在[0,1]范围内的标量值,用以表示样本被发送到左或右分支的概率。用
使用内核大小为1×1的一个卷积层,后面再跟着一个global context block[4]。global context block是简化后的NL block[44]和Squeeze-Excitation (SE) block [16]的改良版,其在context modeling和fusion步骤中与简化后的NL block共享相同的设置,与SE block共享transform步骤。这样,上下文信息就被合并来更好地描述目标。在这之后,使用一个global average pooling[27]、element-wise square-root和L2 normalization[28],以及一个带有sigmoid激活函数的全连接层去生成一个值在[0,1]范围内的标量值,用以表示样本被发送到左或右分支的概率。用![]() 表示第j个样本
表示第j个样本![]() 被送到由分支routing module
被送到由分支routing module ![]() 产生的右子分支的输出概率,其中
产生的右子分支的输出概率,其中![]() ,
,![]() (因为二叉树的第k层最多有2k-1个结点)。因此,样本
(因为二叉树的第k层最多有2k-1个结点)。因此,样本![]() 被送到左分支的概率为
被送到左分支的概率为![]() 。如果概率
。如果概率![]() 大于0.5,我们倾向于右路径而不是左路径;否则,左分支将主导最后的决策。
大于0.5,我们倾向于右路径而不是左路径;否则,左分支将主导最后的决策。
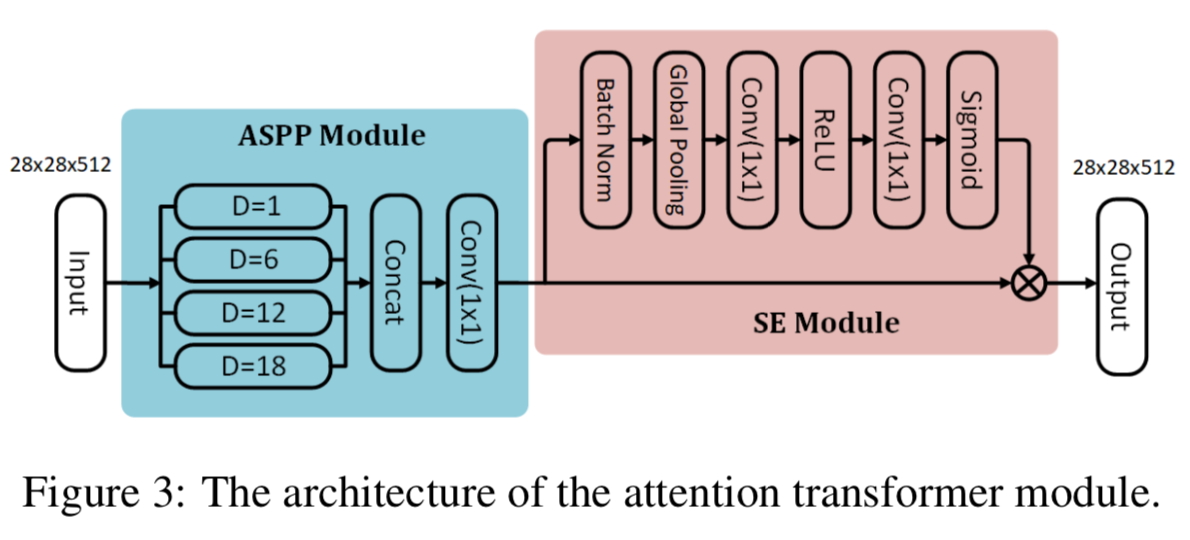
Attention transformer. 注意力转换器模块用于强制网络捕捉判别特征,见图3。根据深度网络[30]的经验接受域远小于理论接受域的事实,具有区分度的表征应该是由我们所提出的树状结构的新层次上的更大的接受域形成的。为此,我们将 Atrous Spatial Pyramid Pooling (ASPP) 模块[5]集成到注意力转换器中。具体来说,ASPP模块提供了不同的特征图,每个特征图都有不同的尺度/接受域和注意模块。然后,通过4个dilated rates不同的平行dilated卷积,即1,6,12,18,生成多尺度特征图。在并行扩张卷积层之后,通过一个带有1×1内核和stride=1的卷积层来融合串联的特征映射。在ASPP模块之后,我们插入一个注意力模块,该模块使用 batch normalization(BN)层[19]、全局平均池化(GAP)层、全连接(FC)层和ReLU激活函数、FC层和sigmoid函数生成一个大小为RC×1×1的通道注意映射。这样,网络就被引导去关注有意义的特征以获得准确的结果。
Label prediction. 对于ACNet模型上的每个叶结点,我们使用标签预测模块![]() (i=1,…,2h-1)去预测目标xj的从属类别,可见图2。让
(i=1,…,2h-1)去预测目标xj的从属类别,可见图2。让![]() 表示在第k层,目标xj从根节点传到第i个节点的累积概率。比如,如果从根节点到结点
表示在第k层,目标xj从根节点传到第i个节点的累积概率。比如,如果从根节点到结点![]() 在树上的路径为
在树上的路径为![]() ,即目标xj总是被送到左孩子分支,即
,即目标xj总是被送到左孩子分支,即![]() 。如图2所示,标签预测模块由一个batch normalization层、一个核大小为1×1的卷积层、一个maxpooling层、一个sqrt和L2 normalization层和一个全连接层组成。然后,第j个目标xj的最终预测结果
。如图2所示,标签预测模块由一个batch normalization层、一个核大小为1×1的卷积层、一个maxpooling层、一个sqrt和L2 normalization层和一个全连接层组成。然后,第j个目标xj的最终预测结果![]() 被计算为 所有叶节点预测值与传递的分支routing modules生成的累积概率相乘的和,即
被计算为 所有叶节点预测值与传递的分支routing modules生成的累积概率相乘的和,即![]() (即最后一层的2h-1个叶结点的结果)。强调
(即最后一层的2h-1个叶结点的结果)。强调![]() ,即xj属于所有从属类的置信度和为1(即预测类的概率总和为1)
,即xj属于所有从属类的置信度和为1(即预测类的概率总和为1)
![]()
其中![]() 是叶结点层第i个结点的累积概率(即从根节点到该叶子结点的概率)。下面使用一个简短的描述证明
是叶结点层第i个结点的累积概率(即从根节点到该叶子结点的概率)。下面使用一个简短的描述证明![]()
Proof. ![]() 是第k层中第i个分支routing module
是第k层中第i个分支routing module ![]() 的累积概率。因此
的累积概率。因此![]() 相应左右孩子的累积概率分别表示为
相应左右孩子的累积概率分别表示为![]() 和
和![]() 。首先,我们说明累积概率
。首先,我们说明累积概率![]() 和
和![]() 的和等于其父节点
的和等于其父节点![]() 的累积概率。即:
的累积概率。即:

同时,由于ACNet中的完全二叉树![]() ,我们有
,我们有![]() 。然后可以进一步得到
。然后可以进一步得到![]() 。该过程是迭代执行的,有
。该过程是迭代执行的,有![]() 。除此之外,因为类别预测
。除此之外,因为类别预测![]() 由softmax层生成(可见图2),所以有
由softmax层生成(可见图2),所以有![]() 。因此:
。因此:

如图2所示,当图像中出现遮挡时,ACNet仍能够定位有区分度的目标parts和鸟的上下文信息。尽管FGVC中总是存在较高的类内视觉方差,ACNet使用一个从粗到细的层次特征学习过程来利用有区分度的特征进行分类。这样,树结构中的不同分支关注不同的细粒度对象区域,以获得准确的结果。
3.2. Training
Data augmentation. 在训练阶段,我们使用裁剪和翻转操作来增强数据,以建立一个稳健的模型来适应对象的变化。也就是说,我们首先重新缩放原始图像,使其较短的边为512像素。之后,我们随机裁剪大小为448×448的patches,然后随机翻转,生成训练样本。
Loss function. 我们的ACNet的损失函数由两部分组成,即叶节点预测的损失,以及最终预测的损失——由所有叶节点预测的总和计算得出。也就是说:
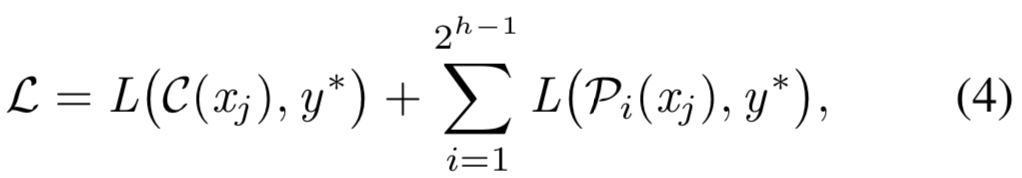
其中h是树![]() 的高度,
的高度,![]() 是最终预测
是最终预测![]() 的负对数似然损失,ground truth标签为y*,
的负对数似然损失,ground truth标签为y*,![]() 为第i个叶结点预测结果的负对数似然损失,ground truth标签为y*。
为第i个叶结点预测结果的负对数似然损失,ground truth标签为y*。
Optimization. ACNet方法中的backbone网络是在ImageNet数据集上进行预训练的。此外,使用“xavier”方法[14]随机初始化附加卷积层的参数。整个训练过程由两个阶段组成。
第一阶段,截断后的VGG-16网络中的参数是固定的,其他参数用60个epoch进行训练。在训练中,batch大小设置为24,初始学习率为1.0。学习率在第10、20、30、40个epochs逐渐除以4。
在第二阶段,我们对整个网络进行200个epochs的微调。我们在训练中使用批大小16,初始学习率为0.001。学习率在第30、40、50个时期逐渐除以10。
我们使用SGD算法训练网络,其momentum为0.9,第一阶段权重衰减为0.000005,第二阶段权重衰减为0.0005。
4. Experiments
在CUB-200-2011[42]、Stanford Cars[25]和Aircraft[32] 3个FGVC数据集上进行了实验,验证了该方法的有效性。我们的方法在Caffe库[22]中实现。所有模型均在有着英特尔3.26 GHz处理器、32GB内存、和一个Nvidia V100 GPU的工作站上进行训练。
4.1. Evaluation on the CUB-200-2011 Dataset
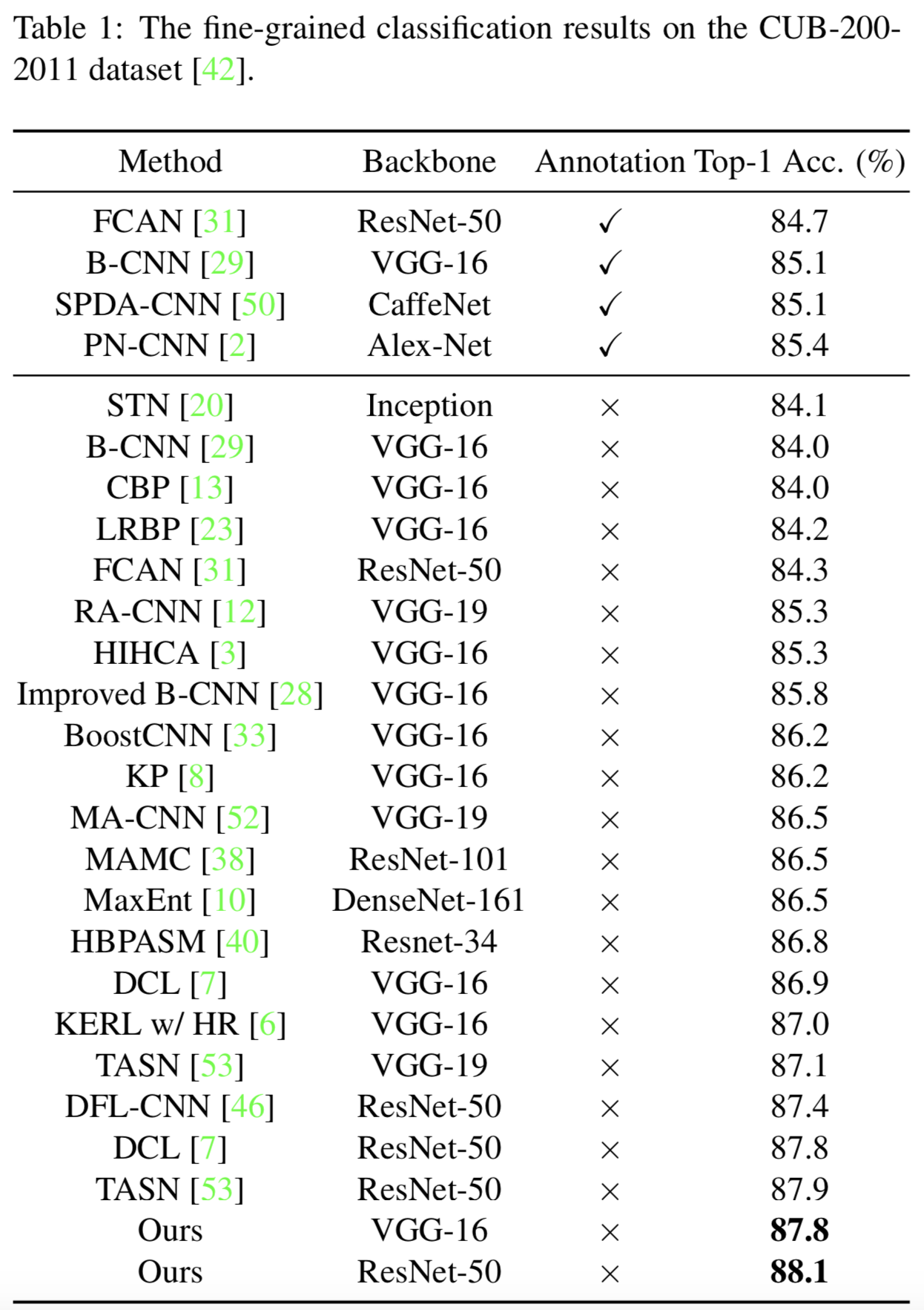
Caltech-UCSD鸟类数据集(CUB-200-2011)[42]包含11,788张标注图像,包括5,994张用于训练的图像和5,794张用于测试的图像。细粒度分类结果如表1所示。如表1所示,在CUB-200-2011数据集上,同时使用对象级标注和part级标注的最佳监督方法PN-CNN[2]的效果是85.4%的top-1准确度。在没有part级标注的情况下,MAMC[38]利用两个注意力分支学习不同区域的有区分度的特征,获得了86.5%的top-1准确率。KERL w/ HR[6]设计了单一的深度门控图神经网络学习有区分度的特征,取得了更好的性能,得到87.0%的top-1准确度。与目前最先进的弱监督方法[6,10,38,46,7,53]相比,我们的方法在不同backbone下的top-1准确率分别达到87.8%和88.1%。这要归功于设计的注意力转换器模块和从粗到细的层次特征学习过程。
4.2. Evaluation on the Stanford Cars Dataset
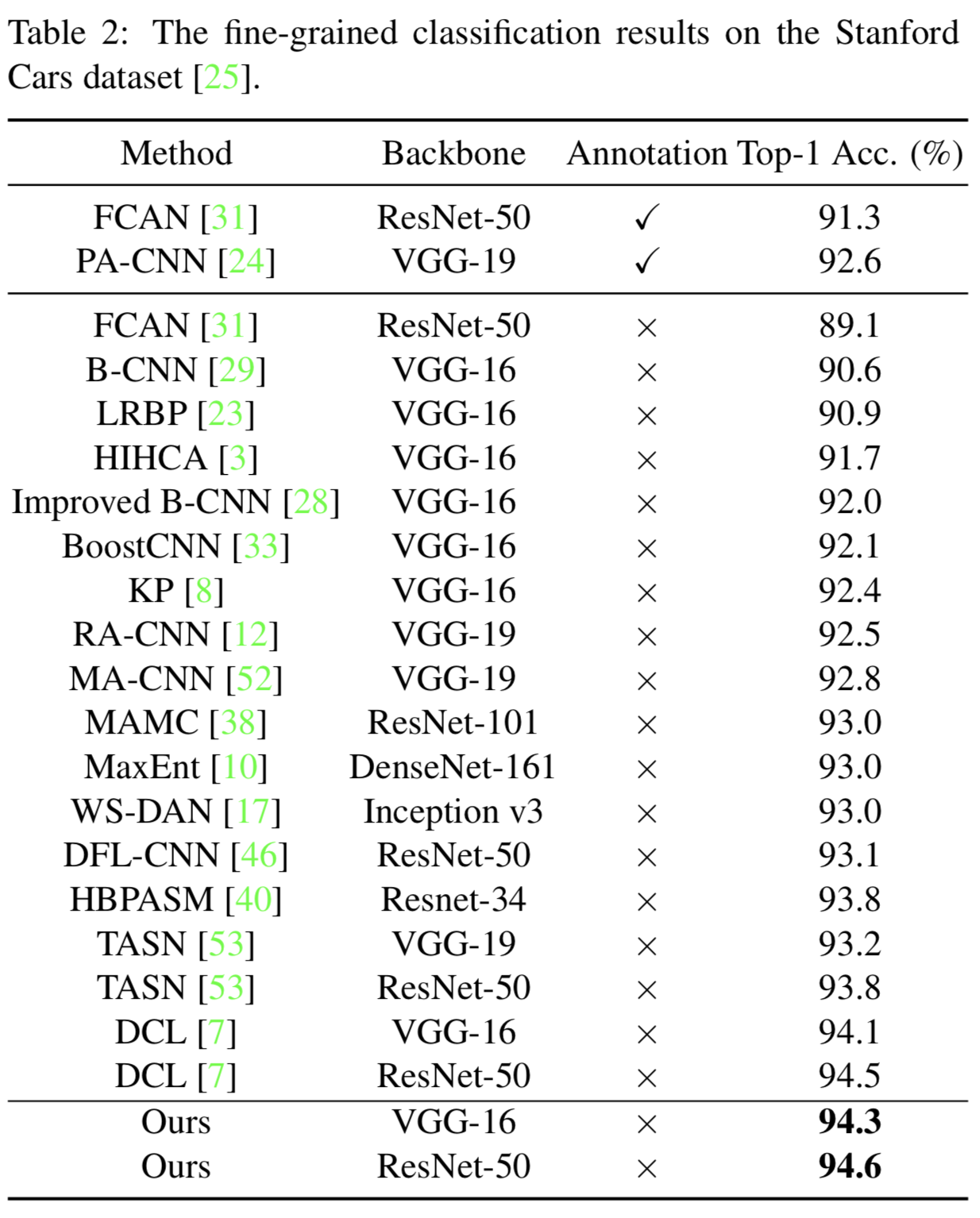
Stanford Cars数据集[25]包含来自196个类的16,185张图像,由8,144张图像组成用于训练,8,041张图像用于测试。从属类别由汽车的制造商、型号和年份决定。如表2所示,之前使用part级标注的方法(即FCAN[31]和PA-CNN[24])的top-1准确率均小于93.0%。最近的弱监督方法WS-DAN[17]采用了复杂的Inception V3 backbone[39],并设计了注意力引导的数据增强策略来利用有区分度的对象parts,实现了93.0%的top-1准确度。在不使用任何特殊的数据增强策略的情况下,我们的方法获得了最好的top-1精度,即VGG-16骨干为94.3%,ResNet-50骨干为94.6%。
4.3. Evaluation on the Aircraft Dataset
Aircraft数据集[32]是由10,000张标注图像组成的100个不同的飞机变体的细粒度数据集,该数据集分为两个子集,即训练集有6667张图像和测试集有3333张图像。具体来说,分类标签由飞机的型号、Variant、Family和制造商决定。评价结果见表3。我们的ACNet方法优于大多数比较方法,特别是在相同的VGG-16 backbone下。此外,我们的模型表现与最先进的方法DCL[7]相当,VGG-16 backbone的top-1精度为91.2% vs 91.5%,而renet-50 backbone的top-1精度为93.0% vs 92.4%。在我们的树形结构![]() 中,沿着根到叶的不同路径进行操作的重点是利用不同目标区域的有区分度特征,这有助于彼此在FGVC中获得最佳的性能。
中,沿着根到叶的不同路径进行操作的重点是利用不同目标区域的有区分度特征,这有助于彼此在FGVC中获得最佳的性能。
4.4. Ablation Study
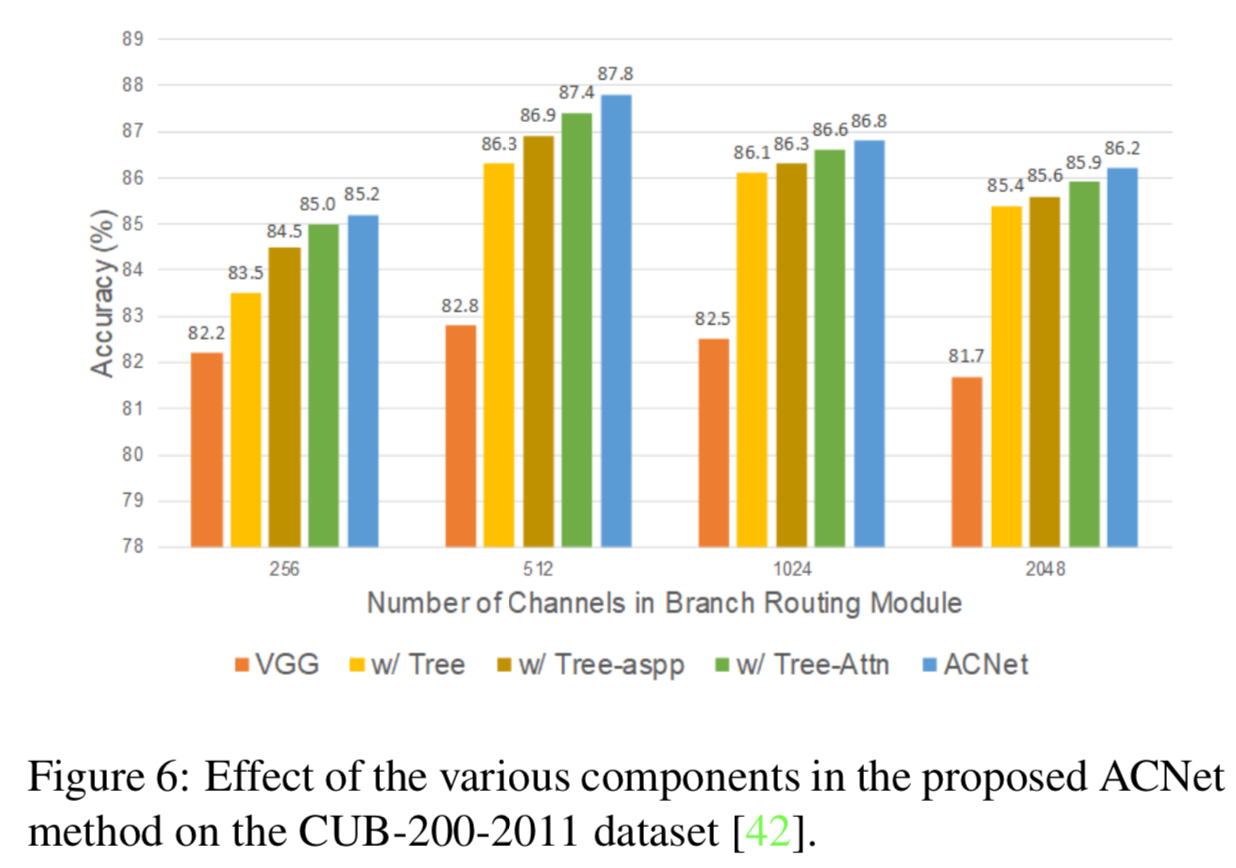
我们研究了ACNet的一些重要参数和不同组成成分对CUB-200-2011数据集[42]的影响。值得注意的是,我们在实验中使用了VGG-16 backbone。采用Grad-CAM方法[36]生成热图,对分支routing和叶节点的响应进行可视化。
Effectiveness of the tree architecture ![]() . 为了验证树型架构设计的有效性,我们构建了ACNet方法的两个变体,即VGG和w/Tree。具体来说,我们只使用VGG-16 backbone网络进行分类,构建VGG方法,并进一步整合树型架构,形成w/Tree方法。评估结果报告在图6中。我们发现使用树型结构可以显著提高精度,即top-1精度提高3.025%,这证明了在我们的ACNet方法中所设计的树型结构
. 为了验证树型架构设计的有效性,我们构建了ACNet方法的两个变体,即VGG和w/Tree。具体来说,我们只使用VGG-16 backbone网络进行分类,构建VGG方法,并进一步整合树型架构,形成w/Tree方法。评估结果报告在图6中。我们发现使用树型结构可以显著提高精度,即top-1精度提高3.025%,这证明了在我们的ACNet方法中所设计的树型结构![]() 的有效性。
的有效性。
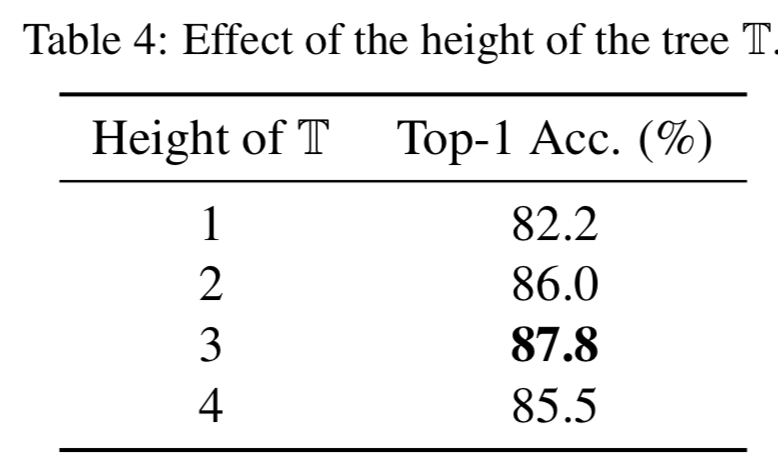
Height of the tree ![]() . 为了探究树的高度
. 为了探究树的高度![]() 的影响,我们在表4中构造了四个不同高度的树变体。值得注意的是,当树的高度设为1时,树
的影响,我们在表4中构造了四个不同高度的树变体。值得注意的是,当树的高度设为1时,树![]() 退化为单个节点,即只使用backbone网络VGG-16进行分类。如表4所示,我们发现我们的ACNet在树高为3时表现最好,top-1准确率为87.8%。当h≤2时,ACNet模型的参数数量有限,不足以表示从属类别的显著变化。然而,如果我们设置h = 4,过多的参数和有限的训练数据会导致我们的ACNet模型过拟合,导致top-1准确率下降2.3%。为了验证我们的假设,我们在图5中可视化ACNet中高度为4的所有叶节点的响应。我们发现一些叶节点几乎集中在相同的区域(请参阅第3和第4列)。
退化为单个节点,即只使用backbone网络VGG-16进行分类。如表4所示,我们发现我们的ACNet在树高为3时表现最好,top-1准确率为87.8%。当h≤2时,ACNet模型的参数数量有限,不足以表示从属类别的显著变化。然而,如果我们设置h = 4,过多的参数和有限的训练数据会导致我们的ACNet模型过拟合,导致top-1准确率下降2.3%。为了验证我们的假设,我们在图5中可视化ACNet中高度为4的所有叶节点的响应。我们发现一些叶节点几乎集中在相同的区域(请参阅第3和第4列)。

Effectiveness of leaf nodes. 为了分析单个叶子节点的有效性,我们分别计算高度为3的单个叶子预测的准确性。四个单独叶节点在CUB-200-2011上的准确率分别为85.8%、86.2%、86.7%和87.0%。结果表明,所有叶节点的信息都是完整的,融合后的结果更准确(87.8%)。如图4所示,我们观察到不同的叶子节点集中在图像的不同区域。例如,第一列对应的叶节点更关注背景区域,第二列对应的叶节点更关注头部区域,其他两个叶节点对翅膀和尾巴的斑块更感兴趣。不同的叶节点可以帮助彼此构建更有效的模型,以获得更准确的结果。

Asymmetrical architecture of the tree ![]() . 为了探索
. 为了探索![]() 中的结构设计,我们构造了两种变体,一种是对称的结构,另一种是不对称的结构,将树T的高度设为3。评价结果见表5。可以看出,本文提出的方法在对称结构下的top-1精度达到86.2%。如果采用非对称结构,top-1的准确率提高了1.6%至87.8%。我们推测,不对称的结构能够融合不同的特征和不同的接受域,从而获得更好的性能。
中的结构设计,我们构造了两种变体,一种是对称的结构,另一种是不对称的结构,将树T的高度设为3。评价结果见表5。可以看出,本文提出的方法在对称结构下的top-1精度达到86.2%。如果采用非对称结构,top-1的准确率提高了1.6%至87.8%。我们推测,不对称的结构能够融合不同的特征和不同的接受域,从而获得更好的性能。

Effectiveness of the attention transformer module. 我们构建了ACNet模型的一个变体“w/ Tree-Attn”,以验证注意转换器模块的有效性,可见图6。具体来说,我们在“w/ Tree”方法中添加了transformer模块中的注意块来构造“w/ Tree-attn”方法。如图6所示,“w/Tree-attn”方法的表现始终优于“w/ Tree”方法,在不同通道数量下都能产生更高的top-1准确度,平均提高0.4%的top-1准确度,说明注意力机制对FGVC是有效的。
为了进一步研究ASPP模块在我们所提出的模型中的作用,我们还采用了ACNet模型的变体“w/ Tree-ASPP”方法,其中唯一的区别在于注意转换模块中使用的是一个卷积层还是ASPP模块。如图6所示,使用ASPP模块的注意转换器比只使用一个卷积层的注意转换器精度更高。结果表明,ASPP模块通过不同dilated率的并行dilated卷积层提高了整体性能。其中,“w/ Tree-ASPP”方法平均提高了0.5%的top-1精度。我们可以得出结论,ASPP模块中的多尺度嵌入和不同的dilated卷积有助于帮助所提出的树状网络获得鲁棒性能。
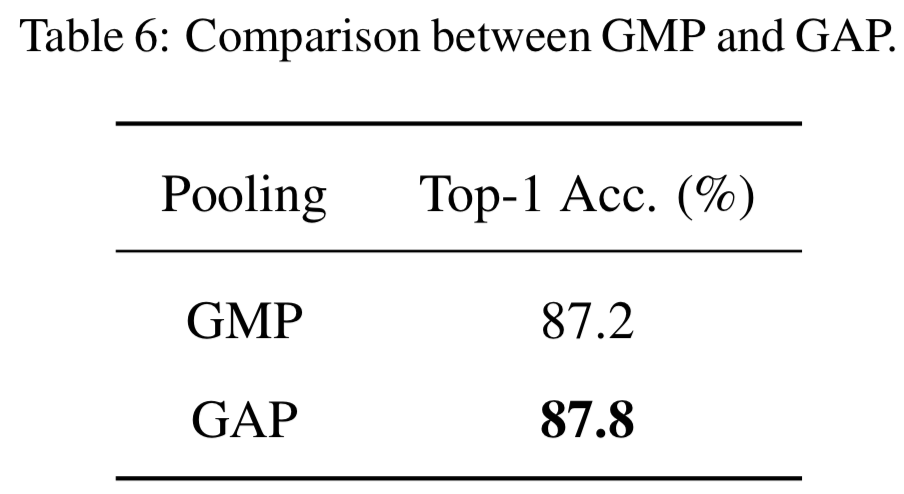
Components in the branch routing module. 我们在图6中分析了分支routing模块中的global context block[4]的有效性。我们的ACNet方法在不同信道数量的分支routing模块中产生最好的结果;而去掉全局上下文块后,top-1的准确率平均下降了0.275%。同时,我们也在表6中研究了分支路由模块中pooling策略的有效性。我们观察到,在CUDE-200-2011数据集上,使用全局最大池化(GMP)而不是全局平均池化(GAP)导致top-1精度下降0.6%。我们推测,GAP操作鼓励过滤器关注高平均响应区域,而不是唯一的最大响应区域,这能够整合更多的上下文信息,以获得更好的性能。
Coarse-to-fine hierarchical feature learning process. 分支routing模块侧重于不同级别的不同语义区域(例如,不同的对象部分)或上下文信息(例如,背景),例如图2中的![]() 、
、![]() 和
和![]() 。如图7所示的Bobolink示例,
。如图7所示的Bobolink示例,![]() 模块在level-1关注整个鸟类区域;
模块在level-1关注整个鸟类区域;![]() 和
和![]() 模块在level-2集中于鸟的翅膀和头部区域。如图5第一行所示,四个叶子节点在level-3上关注几个细粒度对象parts,例如头部区域的不同part。通过这种方式,我们的ACNet使用从粗到细的层次特征学习过程来利用有区分度的特征以获得更准确的结果。这一现象表明,我们在树形
模块在level-2集中于鸟的翅膀和头部区域。如图5第一行所示,四个叶子节点在level-3上关注几个细粒度对象parts,例如头部区域的不同part。通过这种方式,我们的ACNet使用从粗到细的层次特征学习过程来利用有区分度的特征以获得更准确的结果。这一现象表明,我们在树形![]() 架构下的分层特征提取过程,逐渐使我们的模型专注于更有区分度的对象细节区域。
架构下的分层特征提取过程,逐渐使我们的模型专注于更有区分度的对象细节区域。

5. Conclusion
本文提出了一种用于弱监督FGVC的注意力卷积二叉神经树(ACNet)。具体来说就是在树状网络中,利用沿边卷积运算中插入的注意力转换器,不同的根到叶路径关注不同的判别区域。最终的决策是通过对叶节点的预测进行max-voting产生的。在几个有挑战性的数据集上的实验表明了ACNet的有效性。我们详细介绍了如何使用从粗到细的层次特征学习过程来设计树形结构。