
每天给你送来NLP技术干货!
来自:美团技术团队

经典的细粒度情感分析(ABSA,Aspect-based Sentiment Analysis)主要包含三个子任务,分别为属性抽取、观点抽取以及属性-观点对的情感倾向判定三个级联任务。
本文介绍了美团到店到餐应用算法团队通过结合学界最先进的阅读理解、注意力机制等方面的实体抽取、情感分析经验,解决到餐(菜品,属性,观点,情感)四元组抽取问题,并在多个业务场景应用落地,希望能对从事相关工作的同学有所帮助或启发。
-
一、背景
-
二、目标回顾
-
2.1 业务问题
-
2.2 技术调研
-
2.3 技术目标
-
2.4 主要挑战
-
-
三、细粒度情感分析实践
-
3.1 Pipeline方法
-
3.2 联合学习
-
-
四、在到餐业务中的应用
-
4.1 模型效果对比
-
4.2 业务应用场景
-
-
五、未来展望
一、背景
作为一家生活服务在线电子商务平台,美团致力于通过科技链接消费者和商户,努力为消费者提供品质生活。到店餐饮(简称到餐)作为美团的核心业务之一,是满足用户堂食消费需求、赋能餐饮商户在线运营的重要平台,在服务百万级别的餐饮商户和亿级别C端用户的过程中,积累了海量的用户评论信息(User Generated Content, UGC),包含了用户到店消费体验之后的真情实感,如果能够有效提取其中的关键的情感极性、观点表达,不仅可以辅助更多用户做出消费决策,同时也可以帮助商户收集经营状况的用户反馈信息。
近年来,大规模预训练模型(BERT)、提示学习(Prompt)等NLP技术飞速发展。文本分类、序列标注、文本生成各类自然语言处理任务的应用效果得到显著提升,情感分析便是其中最常见的应用形式之一。它的任务目标在于通过NLP技术手段对输入文本进行分析、处理、归纳、推理,给出文本情感极性判定的结果。
按照情感极性判定粒度,可以细分为篇章/整句粒度情感分析、细粒度情感分析(ABSA, Aspect-based Sentiment Analysis)[1]。一般而言,细粒度情感分析的任务目标主要围绕属性(Aspect Term)、观点(Opinion Term)、情感(Sentiment Polarity)三要素展开,可以拆分为属性抽取、观点抽取以及属性-观点对的情感倾向判定三个级联任务[2-5]。例如,对于给定的用户评论“这家店环境不错,但服务很糟糕”,预期的输出结果为(环境,不错,正向)、(服务,糟糕,负向)。

到餐算法团队结合到餐业务供给侧、平台侧、需求侧的业务场景,为核心业务链路的智能化提供高效、优质的算法解决方案,通过算法能力辅助业务降本提效。本文结合到餐B/C端业务场景,探索细粒度情感分析技术在用户评价挖掘方向的应用实践。
二、目标回顾
2.1 业务问题
秉承“帮大家吃得更好,生活更好”的使命,到餐面向消费者提供包括套餐、代金券、买单、预订等在内的丰富产品和服务,并通过黑珍珠餐厅指南、大众点评必吃榜等榜单,以及搜索、查询、评价等,帮助消费者更好地作出消费决策。同时,为商家提供一站式的营销服务,帮助餐饮商户沉淀口碑、获取用户、增加复购等,进而轻松管理餐厅。
随着餐饮连锁化加速、行业竞争格局激烈,商户管理宽幅和难度逐步加大,商户的经营要求更加精细,数据管理意识更加迫切。用户历史评论中蕴含着大量用户消费后的反馈,是情感分析的重要组成部分,不仅能够描述消费感受,同时也能反映出就餐环境的好坏。因此,做好情感分析有利于帮助餐饮门店提升服务质量,也能够更好地促进消费体验。
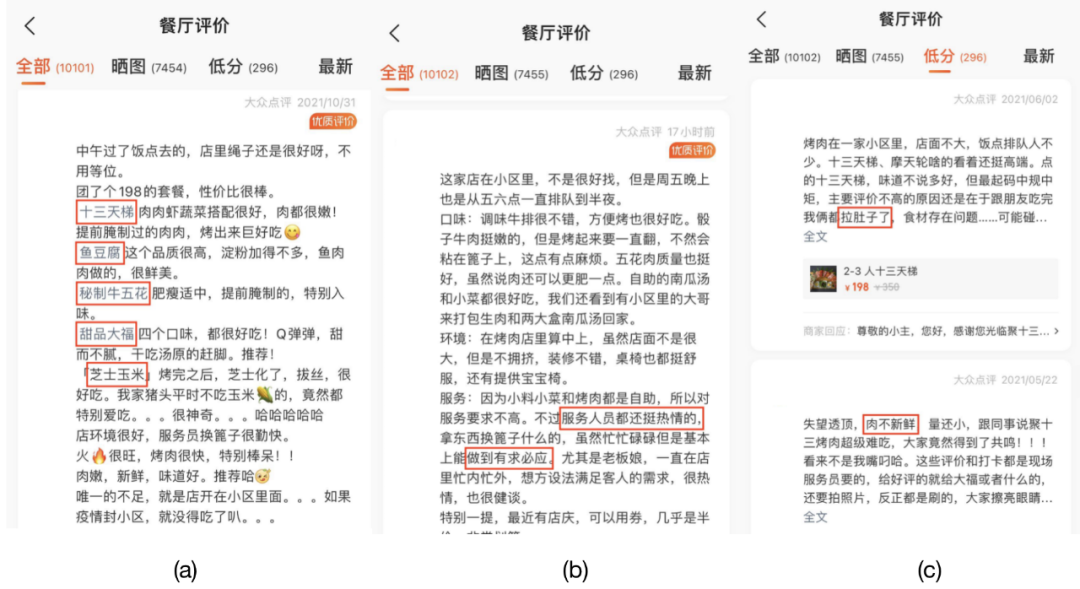
UGC评价分析,主要是从评论文本中挖掘出菜品、服务、食品安全(简称食安)等方面相关信息,获取用户在各个维度的细粒度情感,细致刻画商家的服务现状,如上图2所示。对于餐饮商户,菜品、服务、食安评价分析问题可以拆解如下:
-
菜品评价,主要包括用户评论中的菜品识别、评价属性提取、菜品观点提取、观点情感分类;
-
服务评价,主要包括用户评论中评价属性提取、服务方面观点提取、观点情感分类;
-
食安评价,主要包括用户评论中评价属性提取、食安方面观点提取、观点情感分类。
其中问题2和3是典型的三元组抽取任务,即识别服务或食安方面的(属性,观点,情感)。对于问题1,在服务、食安评价问题的基础上,菜品评价需要识别评论中提及的菜品,相比业界四元组(属性,观点,属性类别,情感)[6]抽取任务,到餐场景下主要为 (菜品,属性,观点,情感)四元组的识别。
2.2 技术调研
在美团内部,我们针对UGC评价分析问题,调研了相关工作成果,主要为基于MT-BERT预训练模型开发了多任务模型,试图解决情感分析中的ACSA (Aspect-Category Setiment Analysis) 问题以及(属性,观点,情感)三元组抽取问题,并实现了句子粒度的情感分类工具开发,同时开源了基于真实场景的中文属性级情感分析数据集ASAP[7-9]。但对于美团到餐业务来说,我们需要基于具体场景提出针对性的解决方案,如四元组抽取任务,不能直接复用其他团队的相关技术和工具,因此有必要建设服务于到餐业务场景的细粒度情感分析技术。
在业界,我们也调研了行业其他团队如腾讯、阿里在细粒度情感分析方面的相关研究。2019年腾讯AI Lab和阿里达摩院合作[3],提出了基于两个堆叠的LSTM和三个组件 (边界引导、情感一致性和意见增强)的模型,将“BIOES”标注体系与情感正向 (Positive)、中性 (Neutral)、负向 (Negative) 结合形成统一标签,可以同时识别属性和情感。同年,阿里达摩院提出了BERT+E2E-ABSA模型结构,进一步解决属性和情感的联合抽取问题[10],同时提出(属性,观点,情感)[2]三元组抽取任务,并给出了两阶段解决框架,首先分别识别出属性(情感融合为统一标签)和观点,然后判断属性-观点是否配对。
自此,业界后续研究开始向三元组联合抽取展开[11-14]。2021年2月,华为云[6]提出(属性,观点,属性类别,情感)四元组抽取多任务模型,其中一个任务识别属性和观点,另一个任务识别属性类别和情感。2021年4月,腾讯[15]引入Aspect-Sentiment-Opinion Triplet Extraction (ASOTE)任务,提出了一个位置感知的BERT三阶段模型,解决了(属性,观点,情感)三元组抽取问题。
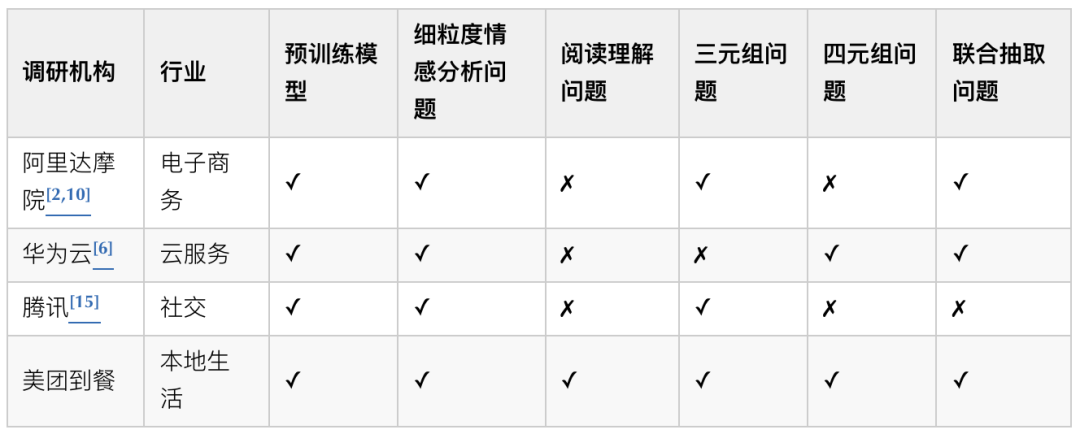
从学术界来看,更关注于如何更好地进行实体抽取、情感分类以及多任务的联合抽取,可能会忽略工业界落地更关注的计算时效性 (如多维度标注与情感维度整合,增加计算、存储资源消耗,在有限资源下时长延迟)、效果准确性 (如任务模块端到端开发,忽略业务的个性化,直接复用导致准确性降低)等方面要求,导致相关技术方法并不能直接应用于业务场景,需要进一步开发完善才能实现业务的落地。
如上表所示,针对以上调研,我们借鉴了美团搜索与NLP部在三元组细粒度情感分析方面的经验,拆解到餐四元组抽取问题,并结合学界最先进的阅读理解、注意力机制等方面的实体抽取、情感分类经验,设计开发了应用于到餐业务的细粒度情感分析解决方案。
2.3 技术目标
如上文所述,菜品评价主要关注菜品、评价属性、菜品观点和观点情感,而服务、食安评价问题,主要关注服务或食安方面的评价属性、观点和情感。就细粒度情感分析任务而言,可以看出,前一个问题涉及四元组信息,而后两个问题仅涉及三元组信息。
假设给定一个长度为的句子,令和,表示句子中标注的菜品实体、评价属性、观点和情感极性,其中情感包括 {正向,中性,负向,未提及}。表示句子中标注的服务或食安方面的评价属性、观点和情感。
对于菜品评价,训练集为,似然函数为:
进一步,对数似然函数为:
其中,超参数。由公式可推测,四元组细粒度情感分析问题可以拆解为:给定文本的菜品实体抽取、描述菜品的评价属性抽取、评价属性对应的观点抽取以及情感分类。
对于服务、食安评价,训练集为,似然函数为:
进一步,对数似然函数为:
其中,超参数。由公式可推测,三元组问题可以拆解为:给定文本的服务或食安属性抽取、评价属性对应的观点抽取以及情感分类。
特别地,公式和最后一项成立的原因是给定属性条件下,与是条件独立的,即:
目标是最大化对数似然函数。总而言之,基于联合概率分布拆解,能够将复杂问题拆分为多个简单问题建模。基于以上分析,建立菜品、服务、食安维度等细粒度情感分析模型。算法的目标就是通过菜品评价、服务评价以及食安评价的建模,从UGC文本中挖掘用户评论信息,如用户消费偏好、用户就餐环境以及场景反馈等。值得一提的是这里提到的四元组和三元组,不仅仅解决以上场景的问题,而是具有更强的泛化性,对于类似场景的细粒度情感分析也同样适用。
在细粒度情感分析中,训练、测试数据主要来源于UGC标注数据。其中,假设UGC文本间标注是独立的,则任意取一定数据的UGC文本进行测试,其余标注为训练样本,进行模型训练。技术评估指标是任务的准确率、召回率以及多类别平均F1值。此外,业务层面主要依赖于文本抽取标签的Badcase率反映算法的准确性。
2.4 主要挑战
由于三元组问题可以看作是四元组问题的子问题,不失一般性,下文将重点阐述四元组相关技术挑战。
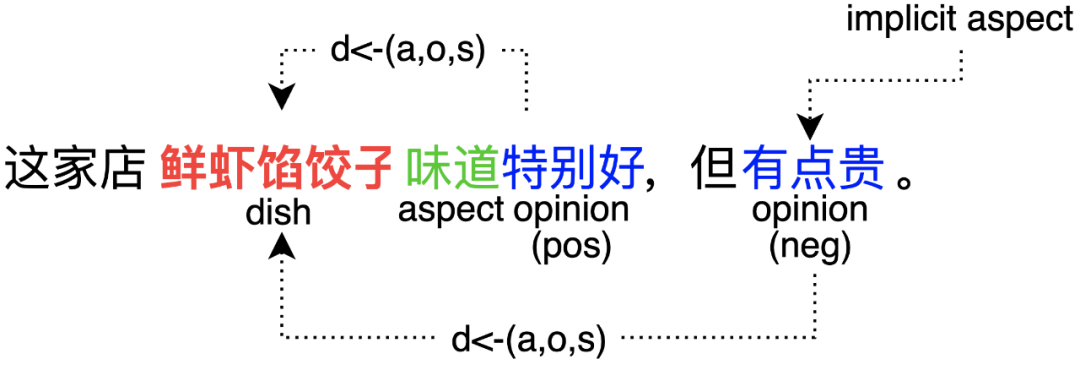
如图3的示例所示,提取的四元组为“鲜虾馅饺子-口味-特别好-正向”和“鲜虾馅饺子-(?)-有点贵-负向”。在到餐场景中,UGC文本细粒度情感分析较复杂,主要存在挑战:给定一条评论,可能包含多个四元组且存在实体间一对多或者多对一的关系,以及可能存在缺失情况;如何准确识别用户所有细粒度评论情感倾向?对于以上挑战,可以拆解为如下问题。
问题1:如何准确识别可能存在的多个四元组?
对于一条存在多个四元组的评论,通过序列标注,直接同时识别多个四元组是不现实的。为此,我们在标注数据预处理时,将评论中四元组分别抽取,各自组成一条独立样本,进行训练、预测。此外,如上文所述,四元组的实体间存在一对多或者多对一的关系,而且实体间的间距通常不固定,存在远程抽取的可能。针对这一问题,一个较有效的实践经验是进行分层分块抽取,即pipeline识别。基于pipeline的方法,如公式所示,则需要分别处理:给定文本,菜品实体抽取 ()、描述菜品的评价属性抽取 ()、评价属性对应的观点抽取 () 以及情感分类 ()。
定义交叉熵损失函数为:
其中,表示每个模块真实label分布,表示分类类别数。
那么,当前问题的损失函数集合为:
其中,目标,将分别针对每一个任务进行逐个最小化。
问题2:如何解决aspect有缺失的四元组识别?
如图3所示,真实场景可能存在四元组的评价属性缺失。针对这类问题,我们将问题拆解为三个任务:给定评价文本,菜品实体抽取 ()、评价观点抽取 () 以及观点和情感的分类 () ,其中是隐藏评价属性的类别。则损失函数为:
同上,在pipeline方法下,目标函数最下化将分别对每一个任务进行最小化。值得一提,如果aspect不存在缺失,这个解决思路实际应用仍然可行。
问题3:如何同时对四元组抽取、识别,减少pipeline方法的错误累计影响?
减少pipeline方法的错误累计影响,典型的解决方案是提出同时处理信息抽取和分类任务,即多任务学习。传统的方法是直接尝试多任务学习的思路,但过程中忽略了实体间依赖的关系,甚至远程关联关系[2]。当前也在尝试直接将四元组转化成多任务学习过程,将来期望通过建立实体间pair或triplet关系,进行联合抽取、识别。
综上,对于问题1和问题2,我们会按照pipeline识别的结果,再利用策略进行抽取结果的优化;对于问题3,整合实体、关系及分类任务,进行联合学习,将有助于减少pipeline方法的错误累计影响。
三、细粒度情感分析实践
3.1 Pipeline方法
如上文2.3的问题2所述,我们采用pipeline的方法,将四元组抽取问题拆解为三个任务,分为实体识别、观点抽取、观点类别和情感分类,如下图4所示:

3.1.1 实体识别
自2018年BERT[16]出现以后,NER模型由传统的LSTM+CRF替换为BERT+CRF(或者BERT+LSTM+CRF),一度是业界NER任务的SOTA模型,近两年来NER任务主要从以下两个方面进行改进:
-
加入额外的特征[17-19]:如字特征、词特征、词性特征、句法特征、知识图谱表征;
-
转换任务形式[20-21]:将NER任务转化为问答 (QA, Question Answering)任务或者机器翻译任务。
考虑到引入额外特征需要构建人工词典,以及转化问答任务形式依赖于人工模板,成本较高,因此采用BERT+CRF模型。
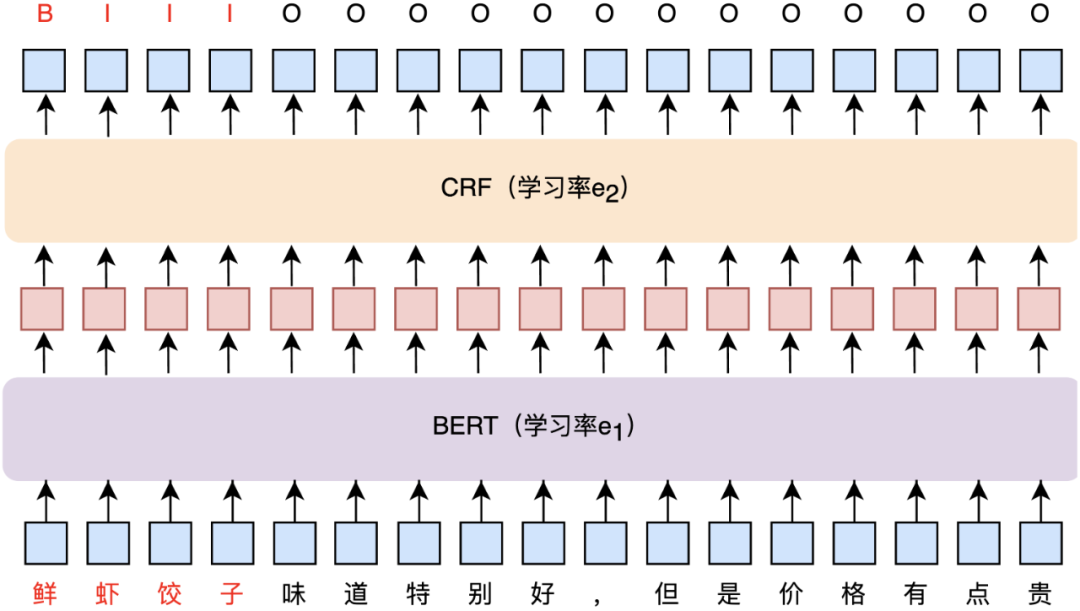
学习率调整,模型策略调优。在实验过程中,我们发现BERT+CRF相比简单的BERT+Softmax效果提升甚微,究其原因,由于预训练模型经过微调之后可以学习到具有明显区分度的特征,导致增加CRF层对实体识别结果几乎没有影响。然而,一个好的CRF转移矩阵显然对预测是有帮助的,可以为最后预测的标签添加约束来保证预测结果的合理性。进一步实验后发现,通过调整BERT和CRF层的学习率,如BERT使用较小的学习率而CRF层使用100倍于BERT的学习率 (即,如图5所示),最终BERT+CRF的效果相比BERT+Softmax有了较明显的提升。此外,在传统NER模型LSTM+CRF基础上,我们也实验了BERT+LSTM+CRF,但效果居然有些许下降,而且预测时间也增加了,因此最终没有引入LSTM层。
3.1.2 观点抽取
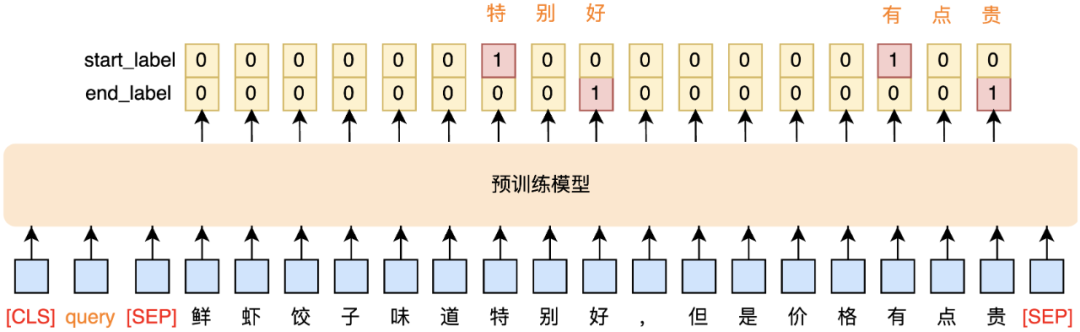
观点抽取任务在业界也称为Target-oriented Opinion Words Extraction(TOWE),旨在从评论句子中抽取出给定目标对应的观点词。观点抽取也可以看作是一种NER任务,但若评论涉及多个实体和观点,如何准确抽取所有“实体-观点”关系是一个技术挑战。借鉴MRC(Machine Reading Comprehension)任务的思想,通过构建合理的Query引入先验知识,辅助观点抽取。
QA任务形式,观点抽取建模。如图6所示,模型整体由预训练层和输出层两部分组成。输出层我们使用了常规QA任务输出,包括开始标签(Start Label)和结束标签(End Label),但需要人工设计Quey。参考论文[20]经验,以图3为例,实验发现Query设计为“找出鲜虾馅饺子口味、口感、分量、食材、卖相、价格、卫生以及整体评价”效果最好,可能融入了观点描述信息,更加有助于观点抽取。考虑到QA任务天然有类别不平衡的问题,因此损失函数引入针对类别不平衡的Focal Loss,用于提升观点抽取模型的效果。由于观点抽取也可以看作是NER任务,故我们尝试将输出层设计为CRF层,但实验效果并不理想,可能由于观点语句长度不一且比较个性化,影响模型识别。另一方面,考虑到Google中文预训练模型BERT是以字粒度为切分,没有考虑到传统NLP中的中文分词,在预训练层我们将BERT模型替换为哈工大开源的中文预训练模型,如BERT-wwm-ext、RoBERTa-wwm等,最终模型效果取得进一步提升。
3.1.3 观点类别和情感分类
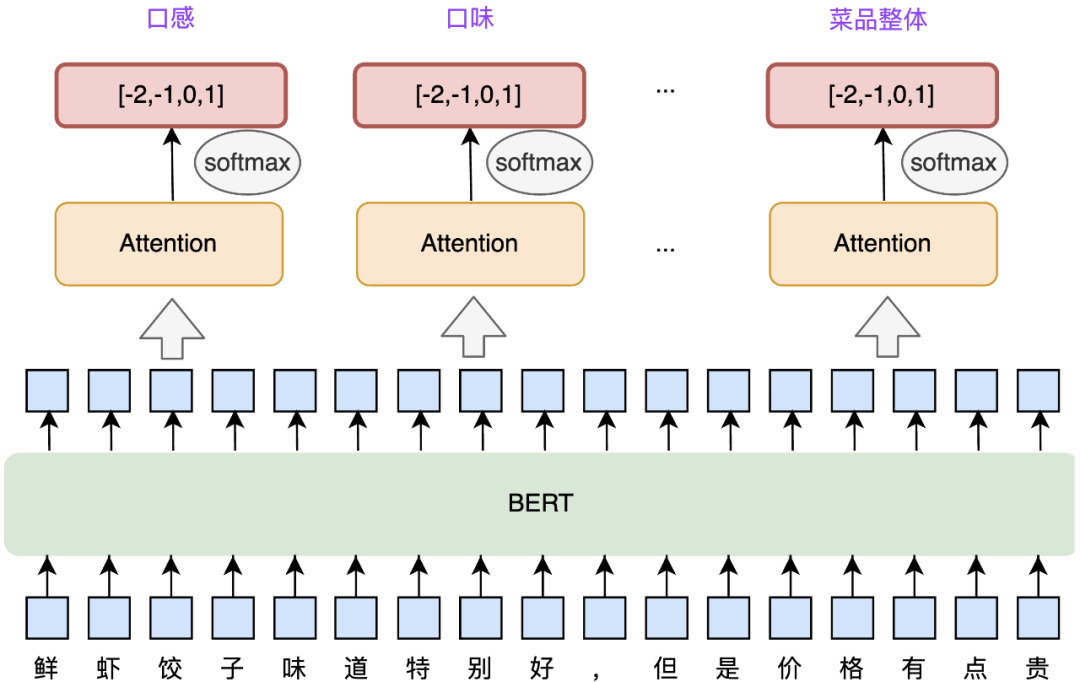
观点类别和情感分类可以看作两个分类任务,其中菜品评价四元组任务的观点类别包含口感、口味、分量、食材、卖相、价格、卫生、菜品整体等8个标签,而情感包含正向、中性、负向、未提及等4个标签,都是业务预定义好的。考虑到用户评论提及某个菜品的观点可能涉及多个维度,若每个维度单独建模,需要构建多个模型,较复杂且维护困难。结合ATAE-LSTM[22]和NLP中心[7-9]情感分析的经验和到餐业务特点,模型整体结构设计为多任务多分类学习框架。
多任务多分类模型,联合建模观点类别和情感。如图7所示,模型整体分为两个部分,分别为BERT共享层和Attention独享层,其中BERT共享层学习观点Embedding表示,Attention独享层学习观点在各个观点类别的情感倾向。考虑到评论中各部分会聚焦不同的观点维度,通过引入Attention结构,使得模型更加关注特定维度相关的文本信息,进而提升整体效果。
3.2 联合学习
pipeline方法的优点是将目标问题拆分为多个子模块问题,对子模块分别优化,通过后处理能在一定程度上解决实体间多对多关系的问题。然而,pipeline方法也会存在一些致命缺陷,主要包括:
-
误差传播,实体识别模块的错误会影响到观点抽取模型的性能;
-
忽略了任务之间的关联性,如实体和观点往往一起出现,如果可以知道观点,那么也能判断出所描述的实体,而pipeline方法显然不能利用这些信息;
-
信息冗余,由于需要对识别出来的实体都要进行观点抽取,以及提取出的观点都要进行分类,产生一些无效的匹配对,提升错误率。
参考业界情感分析联合学习现状,主要为(属性,观点,情感)三元组联合抽取。结合到餐业务场景特点(如挑战2.3的问题2所述),整体设计为两阶段模型,第一阶段为对菜品实体、观点和情感联合训练,第二阶段为对观点进行分类,进而得到四元组识别的结果。
3.2.1 三元组联合抽取
目前在学术界,三元组(属性,观点,情感)联合抽取的方法主要包括序列标注方法[11]、QA方法[5,12]、生成式方法[13,14]等。结合菜品分析场景和pipeline方法中观点抽取模块的经验,我们采取了QA式的联合抽取方法,主要参考模型Dual-MRC[5]。
Dual-MRC模型的改进,三元组联合抽取建模。在模型设计过程中,由于Dual-MRC模型分类情感倾向是对某个属性的整体评价,即一个属性只对应一个情感。然而,在到餐业务场景中,新增了菜品实体的识别,同时UGC评论中存在对同一个菜品实体包含不同观点及情感倾向。如图3所示,“味道特别好”表达了对“鲜虾饺子”正向情感,而“有点贵”显然表达了负面情感。因此,我们对Dual-MRC模型进行了改造,将观点和情感标签整合成统一标签。如图8所示,到餐Dual-MRC整体结构基于双塔BERT模型,通过引入两个Query,左边负责抽取菜品实体,右边负责抽取观点和观点情感,从而实现三元组联合抽取。
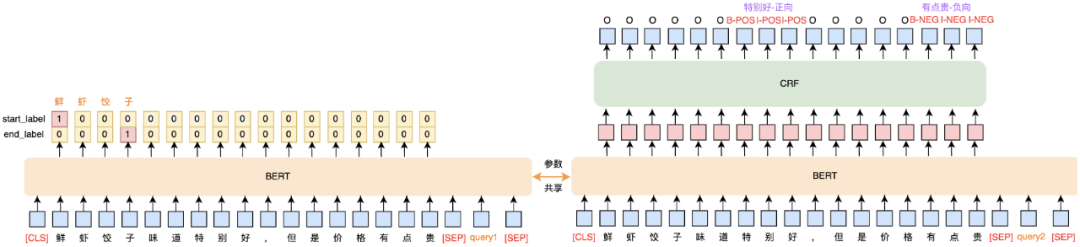
模型结构说明:
-
整体是由两个部分组成,左边BERT抽取菜品实体,右边BERT抽取观点和观点情感,将观点和情感构成统一标签B-{POS,NEU,NEG},I-{POS,NEU,NEG}以及O,其中未提及情感被整合到O标签中;
-
参考pipeline方法经验,构建两个Quey,左边Quey1构建为“找出评论中的菜品”,右边Quey2构建为“找出鲜虾馅饺子口味、口感、分量、食材、卖相、价格、卫生以及整体评价”;
-
训练阶段,对于左边标注的每个菜品实体,都需要重复右边流程,两边模型共享参数进行训练;预测阶段,由于实体不可知,采用pipeline方式,首先左边部分抽取出所有的菜品实体,然后对于每个实体输入到右边部分,抽取出观点和观点情感。
在此基础上,我们也探索了四元组联合抽取的可能,具体操作为对右边Query2进行改造,如“找出鲜虾馅饺子口味评价”,对于每个观点类别都需要构建Query进行预测,从而实现四元组联合抽取。但考虑计算量级较大且耗时较长,最终将观点类别另做预测。
3.2.2 观点类别分类
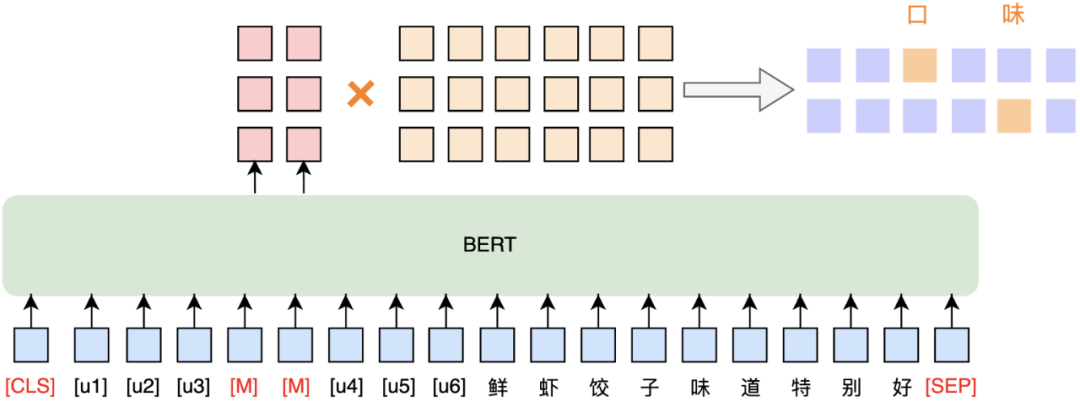
观点类别分类,显然是一个文本分类问题,通常做法是基于BERT分类,取[CLS]位置的Embedding,接一个全连接层和Softmax层即可。在到餐业务场景中,主要面临少样本问题,参考业界NLP少样本解决方法,以基于对比学习的R-drop[23]方法和基于Prompt[24]的第四范式为代表。我们在BERT模型结构基础上,分别实验了Prompt模板方法(如图9所示)和R-drop数据增强 (如图10所示)。其中,Prompt模板主要借鉴P-tuning[25]的思想,采取自动化构建模板的方式,基于MLM任务解决问题。
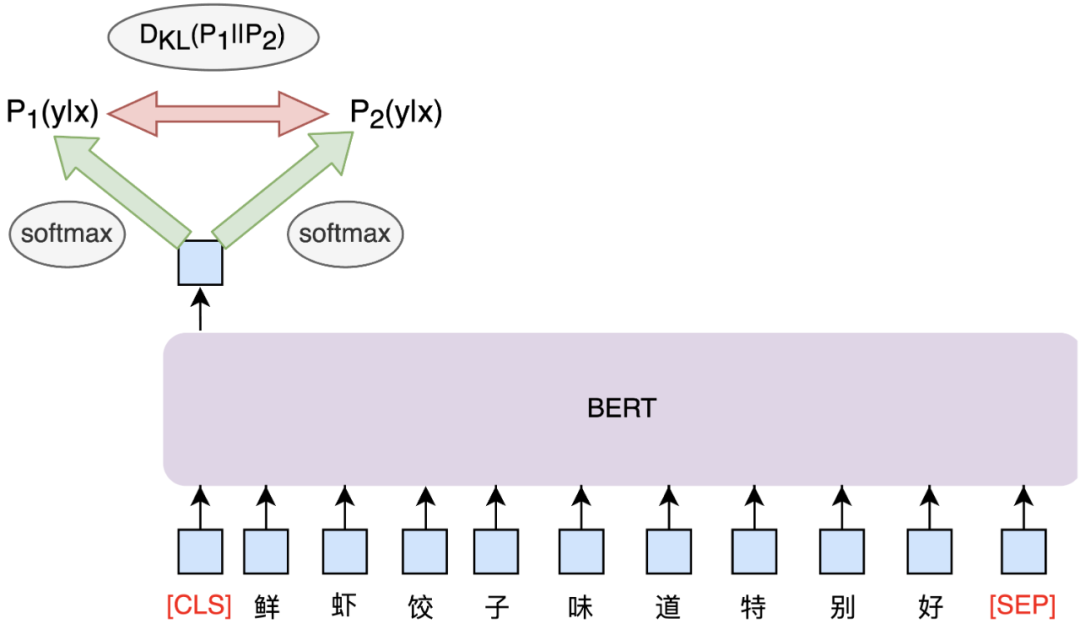
图9中[u1]~[u6]代表BERT词表里边的[unused1]~[unused6],即使用未出现的Token构建模板,Token数目为超参数。实验结果发现,基于BERT的预训练模型,结合P-tuning或R-drop结构,分类效果都能得到一定的提升,且P-tuning的效果略优于R-drop,后续还会持续探索少样本解决方法。
四、在到餐业务中的应用
4.1 模型效果对比
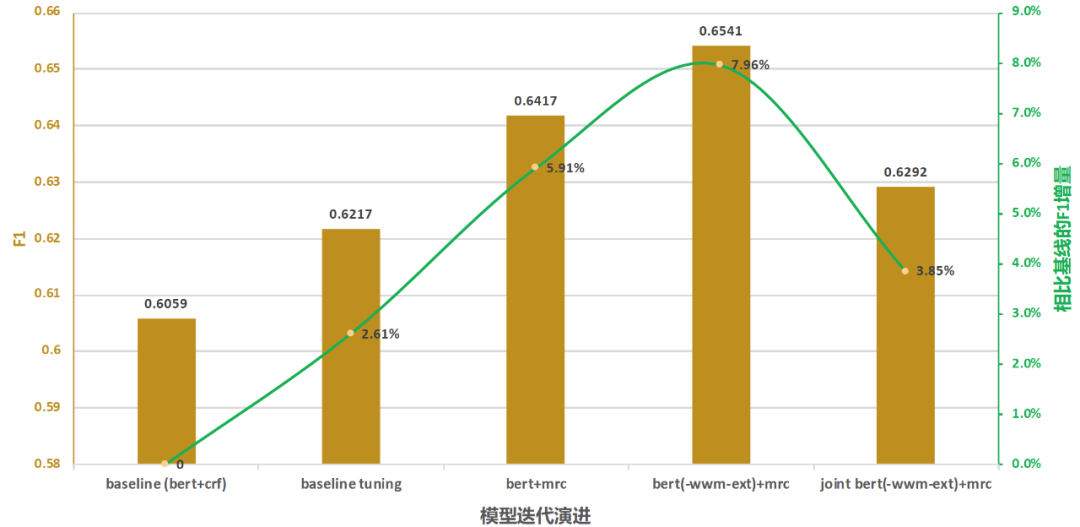
利用到餐的UGC标注数据,对于四元组识别进行了整体效果测评,最终以整体四元组的精确率和召回率计算F1值作为性能评估指标。如图11所示,采用经典的BERT+CRF模型进行实体抽取,在到餐评论标注数据仅达到0.61的F1,经过学习率等调参 (Baseline Tuning)优化之后,F1值提升2.61%。如上文所述,在观点抽取模块中,将序列标注问题转化成问答(QA)问题后,采用BERT+MRC模型,F1显著提升至0.64,提升了5.9%,表明问题转化获得较大收益。此外,采用哈工大中文预训练BERT仍取得一定幅度的提升,F1提升至0.65。注意,图11中的模型迭代表示四元组问题中重点优化模块的模型,最终评测四元组整体效果来进行对比分析。
4.2 业务应用场景
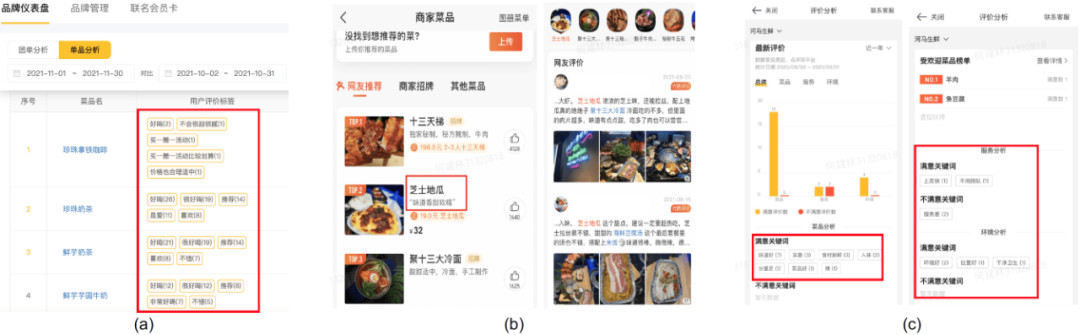
品牌仪表盘
品牌仪表盘作为旗舰店能力的重要环节,提供品牌层面的数据服务,助力生意增长。产品定位为头部餐饮品牌的数据中心,具备基础的数据披露能力,通过量化业务效果,指导商户经营决策。由于大客在平台沉淀了丰富的线上信息(大量的交易/流量/评论数据),可挖掘分析空间较大。应用细粒度情感分析技术从评论数据中挖掘菜品维度、服务维度、食品安全维度相关信息,量化商户经营表现,指导经营动作。关于菜品的用户反馈监控,品牌商户更关注菜品、口味、口感等维度的用户反馈。如上文所述模型迭代后,菜品情感、口味情感、口感情感识别准确率都得到一定的提升。
到餐商户菜品信息优化
随着到餐加强了菜品信息建设,主要包括在生产层面上,整合了商户各来源菜品数据,建设了商户菜品中心,并优化了C端菜品UGC上传功能,有效补充UGC菜品生产;在消费层面上,整合了商户通菜品和网友推荐菜菜品,并基于菜品信息的完善,优化了C端菜品信息的内容聚合及展示消费。同时配合到餐业务,持续通过评价信息生产建设赋能,更多的引导用户从评价生产层面进行商户菜品的描述介绍。主要针对到餐商户菜品关联的评价信息,进行信息联动与展示层面的优化,相比迭代前,有评价菜品覆盖率得到较大的提升。
开店宝评价管理
商家通过提供餐饮服务来获取用户,用户消费后通过评价给商家以反馈,促使商家去不断优化,提供更好的服务,从而获取更多的用户,达到正向循环。评价分析的意义在于建立起评价和餐饮服务之间的通道,实现评价对服务的正向促进循环。通过分析评价内容,帮助商家发现餐厅在菜品、服务、环境等方面,做得好和做得不好的地方,进而针对性的改善。相比迭代前,菜品、服务、环境维度关联评论数得到很大的提升。
五、未来展望
经过近一年的建设,情感分析相关能力不但成功应用到到餐商户经营、供应链等业务,而且优化了多源菜品信息,辅助品牌商户进行用户反馈监控,提升商户服务能力。在联合学习探索上,目前主要将四元组问题转化为两阶段模型,如图11所示,F1值有所下降,仅达到0.63。究其原因,可能是在三元组联合抽取模型中,忽略了实体间的关系,尤其长程关系 (如上文2.4的问题3所述),导致性能不足预期。接下来,将进一步提升情感分析四元组抽取能力,挖掘UGC中用户的核心需求以及重要反馈。在技术方面,将持续进行模型迭代演进,主要涉及:
-
持续优化现有模型,保证质量的同时也要提升效率
实验结果还有很大的改进空间,需要进一步探索模型优化方法,如优化预训练模型,使用MT-BERT等,以及在联合抽取中进一步引入实体间关系,来提升四元组抽取的性能。
-
深度探索情感分析领域,建设四元组联合抽取模型
主要通过改造Query实现四元组抽取,但是计算量级较大,需要探索模型结构优化,减少冗余的计算量,使其满足四元组联合抽取。
-
建设细粒度情感分析通用框架
到餐场景涉及多个情感分析场景,需要建设灵活方便的通用框架,有助于快速支持业务,以及减少资源消耗。
未来,团队将持续优化应用技术,解决到餐业务场景中的情感分析需求。细粒度情感分析是具有挑战和前景的任务,到店餐饮算法团队将和各位读者共同持续探索和研究。
六、参考文献
[1] Liu, B. 2012. Sentiment analysis and opinion mining. Synthesis lectures on human language technologies 5(1):1–167.
[2] Peng, H. Xu, L. Bing, L. Huang, F. Lu, W. and Si, L.2020. Knowing What, How and Why: A Near Complete Solution for Aspect-Based Sentiment Analysis. In AAAI, 8600–8607.
[3] Li, X. Bing, L. Li, P. and Lam, W. 2019a. A unified model for opinion target extraction and target sentiment prediction. In AAAI, 6714–6721.
[4] Zhao, H. Huang, L. Zhang, R. Lu, Q. and Xue, H. 2020. SpanMlt: A Span-based Multi-Task Learning Framework for Pair-wise Aspect and Opinion Terms Extraction. In ACL, 3239–3248.
[5] Y. Mao, Y. Shen, C. Yu, and L. Cai. 2021. A joint training dual-mrc framework for aspect based sentiment analysis. arXiv preprint arXiv:2101.00816.
[6] 华为云细粒度文本情感分析及应用.
[7] 杨扬、佳昊等. 美团BERT的探索和实践.
[8] 任磊,步佳昊等. 情感分析技术在美团的探索与应用.
[9] Bu J, Ren L, Zheng S, et al. ASAP: A Chinese Review Dataset Towards Aspect Category Sentiment Analysis and Rating Prediction. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021.
[10] Xin Li, Lidong Bing, Wenxuan Zhang, and Wai Lam. Exploiting BERT for end-to-end aspect-based sentiment analysis. In W-NUT@EMNLP, 2019.
[11] Xu, L. Li, H. Lu, W. and Bing, L. 2020. Position-Aware Tagging for Aspect Sentiment Triplet Extraction. In EMNLP, 2339–2349.
[12] Chen, S. Wang, Y. Liu, J. and Wang, Y. 2021a. Bidirectional Machine Reading Comprehension for Aspect Sentiment Triplet Extraction. In AAAI.
[13] Yan, H. Dai, J. Qiu, X. Zhang, Z. et al. 2021. A Unified Generative Framework for Aspect-Based Sentiment Analysis. arXiv preprint arXiv:2106.04300.
[14] Wenxuan Zhang, Xin Li, Yang Deng, Lidong Bing, and Wai Lam. 2021. Towards Generative Aspect-Based Sentiment Analysis. In ACL/IJCNLP 2021, 504–510.
[15] Li Yuncong, Fang Wang, Zhang Wenjun, Sheng-hua Zhong, Cunxiang Yin, & Yancheng He. 2021. A More Fine-Grained Aspect-Sentiment-Opinion Triplet Extraction Task. arXiv: Computation and Language.
[16] Devlin, J. Chang, M.-W. Lee, K. and Toutanova, K. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In NAACL-HLT, 4171–4186.
[17] Yue Zhang and Jie Yang. 2018. Chinese ner using lattice lstm. arXiv preprint arXiv:1805.02023.
[18] Li, X. Yan, H. Qiu, X. and Huang, X. 2020. FLAT: Chinese NER Using Flat-Lattice Transformer. arXiv preprint arXiv:2004.11795 .
[19] Tareq Al-Moslmi, Marc Gallofré Ocaña, Andreas L. Opdahl, and Csaba Veres. 2020. Named entity extraction for knowledge graphs: A literature overview. IEEE Access 8 (2020), 32862– 32881.
[20] X. Li, J. Feng, Y. Meng, Q. Han, F. Wu, and J. Li. 2020. A unified MRC framework for named entity recognition. In ACL, 5849–5859.
[21] Jana Strakova, Milan Straka, and Jan Hajic. 2019. Neural architectures for nested ner through linearization. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 5326–5331.
[22] Yequan Wang, Minlie Huang, Li Zhao, and Xiaoyan Zhu. 2016. Attention-based lstm for aspect-level sentiment classification. In Proceedings of the conference on empirical methods in natural language processing, 606–615.
[23] Liang X, Wu L, Li J, et al. R-Drop: Regularized Dropout for Neural Networks[J]. arXiv preprint arXiv:2106.14448, 2021.
[24] P. Liu, W. Yuan, J. Fu, Z. Jiang, H. Hayashi, and G. Neubig. 2021. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. arXiv preprint arXiv:2107.13586.
[25] X. Liu, Y. Zheng, Z. Du, M. Ding, Y. Qian, Z. Yang, and J. Tang. 2021. Gpt understands, too. arXiv preprint arXiv:2103.10385.
七、术语解释

八、作者介绍
储哲、王璐、润宇、马宁、建林、张琨、刘强,均来自美团到店事业群/平台技术部。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!