图片来源:南京大学软件学院COA课程PPT
©author:zzb
Github主页 CSDN主页
文章目录
- 9 高速缓冲存储器(Cache)
- Cache的设计要素
-
- 一、cache容量
- 二、映射功能
-
- 1.直接映射
- 2.关联映射
- 3.组关联映射(介于前面两种方法之间)
- 三、替换算法
-
- 1.最近最少使用算法(LRU)
- 2.先进先出算法(FIFO)
- 3.最不经常使用算法(LFU)
- 4.随机替换算法(Random)
- 四、写策略
-
- 1.写直达
- 2.写回法
- 五、行大小
- 六、cache数目
- 总结
- 总结
9 高速缓冲存储器(Cache)
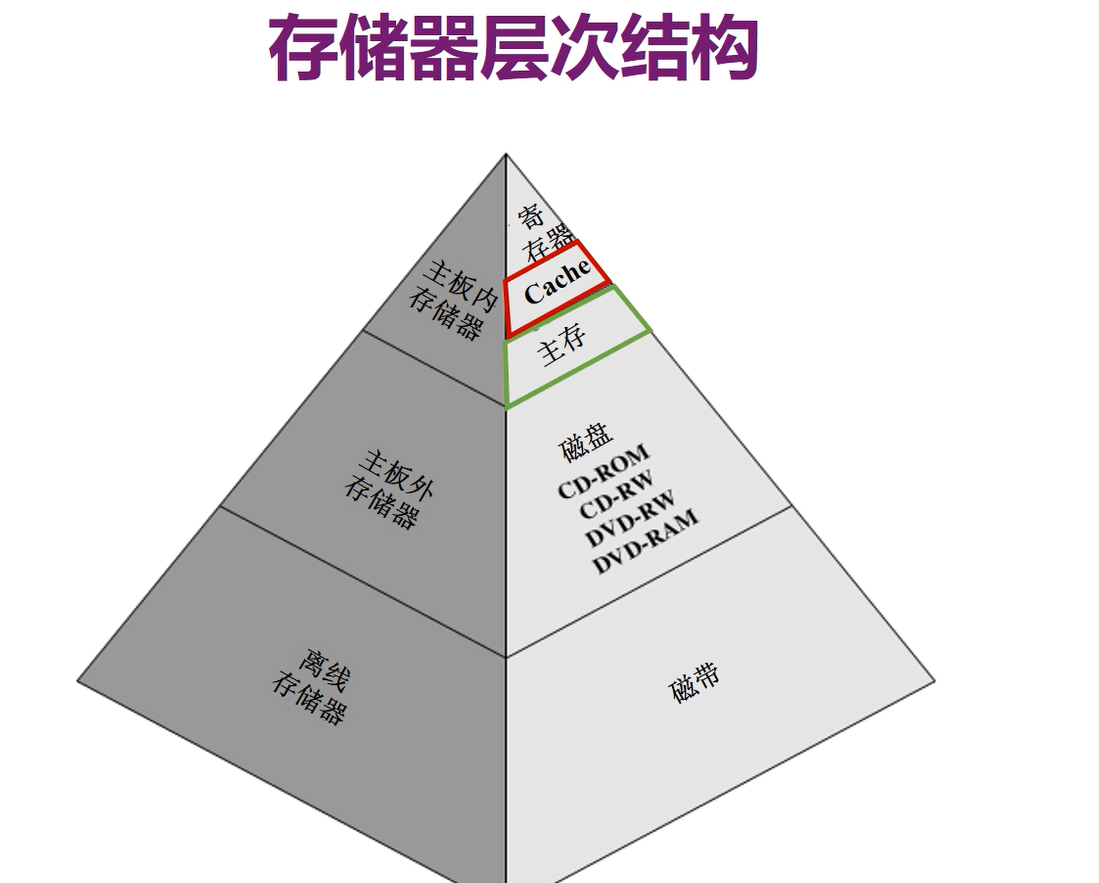

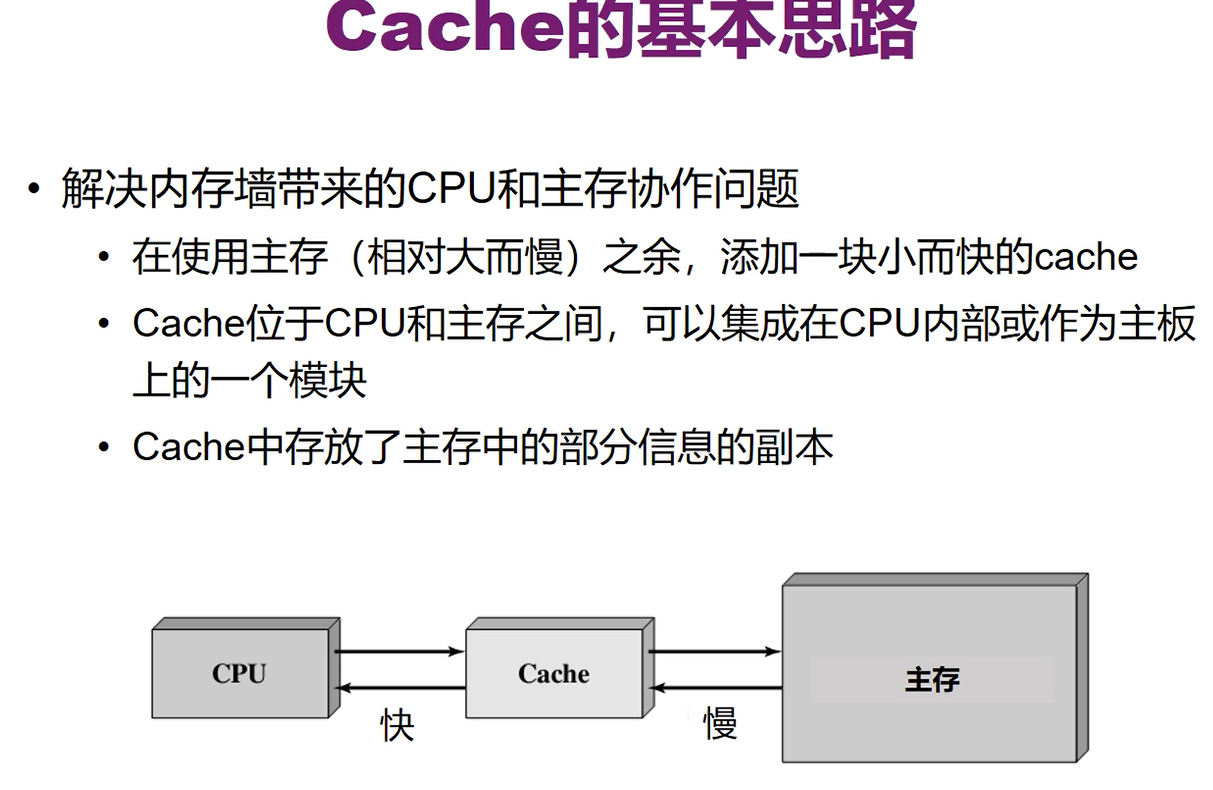
大部分是集成在CPU内部的,存放的还是主存内的信息,是主存内部分信息的副本
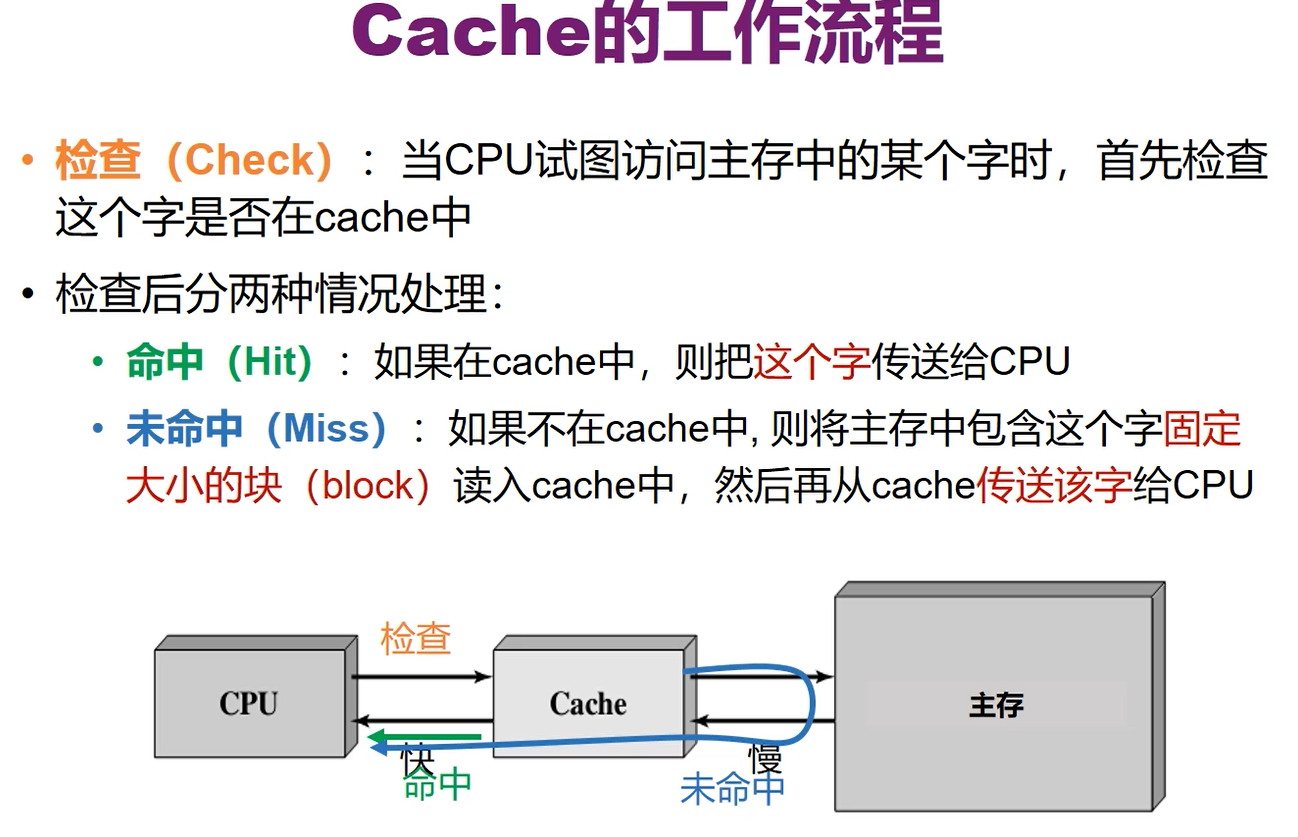
如果不在cache中,那么会将包含这个字的固定大小的块读入cache,然后再从cache中把这个字传给CPU


cache中除了要存内容,还得存这个内容的位置,因为CPU是通过位置来访问主存中的内容的,而不关心其中的内容。
cache不是存放了完整的位置,而是通过tags标记来对应内容在内存中的位置

如果大部分时间都是未命中,那么使用cache后反而时间会更慢,而事实上cache很好的处理了内存墙问题,因此大部分情况应当是命中的
这是由于程序访问的局部性原理,即CPU总是会频繁的访问相同位置或者是相邻位置的内容:
- 时间局部性:在相对短时间内,重复访问相同位置的信息
- 空间局部性:在相对短时间内,会访问相邻存储位置的数据
- 顺序局部性:相邻位置的按顺序的,如访问数组

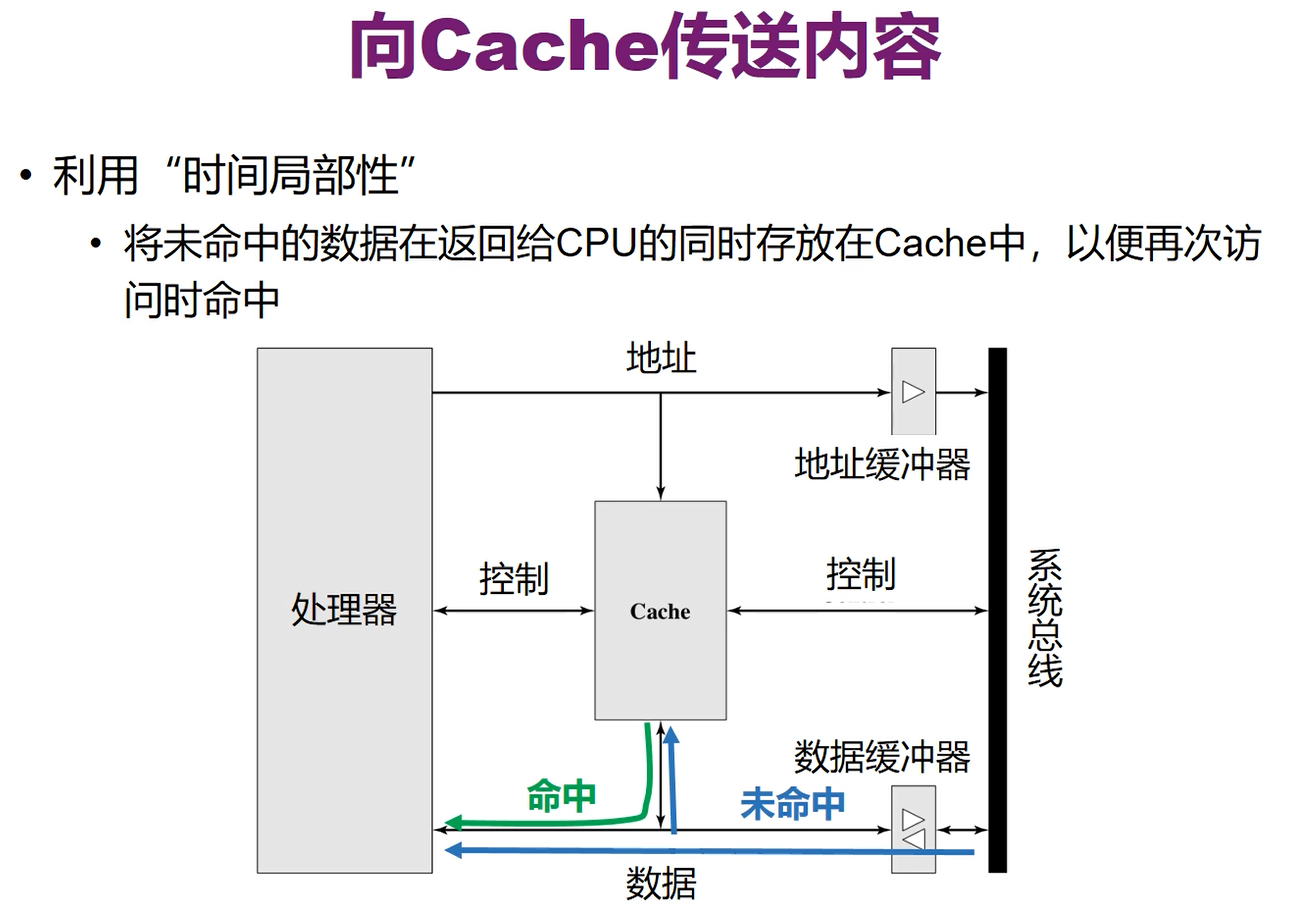
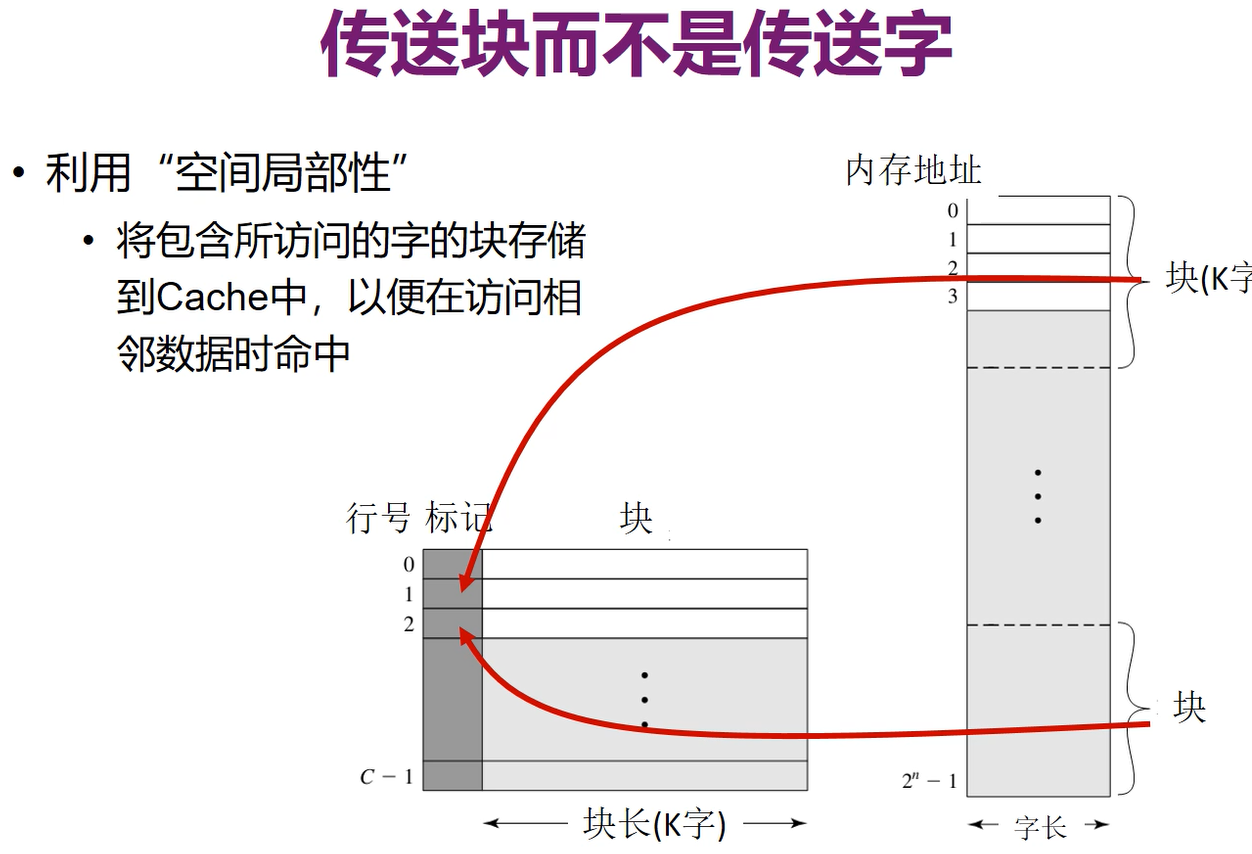
注意这个块是事先就在内存中划分好了(哪一部分属于哪个块都是确定的),要哪个字时,只要把这个字的所在块搬过去,而不是临时从这个字开始再划分块
所以只要想要访问的字所属的块在cache中,那么这个字就在cache中,因此只要对每个块做一个标记(块号)就可以知道有没有命中
cache中每一行是一个块,记录了块的标记和块中的K个字

TA的两个式子,是两种不同的理解,第一行是分为命中和未命中来理解,第二行是分成check检查阶段和到主存取数据阶段来理解的,一般第二行使用更多
Tc很快,Tm相对慢,因此Tc/Tm是比较小的值,所以p是相对很小时就能满足条件。但事实上这个条件虽然小也很难满足,因为cache容量远小于主存容量,p实际上按概率来算应该是cache的容量/主存容量,是非常小的,但之所以能满足,就是因为前面提到的局部性原理
Cache的设计要素

一、cache容量
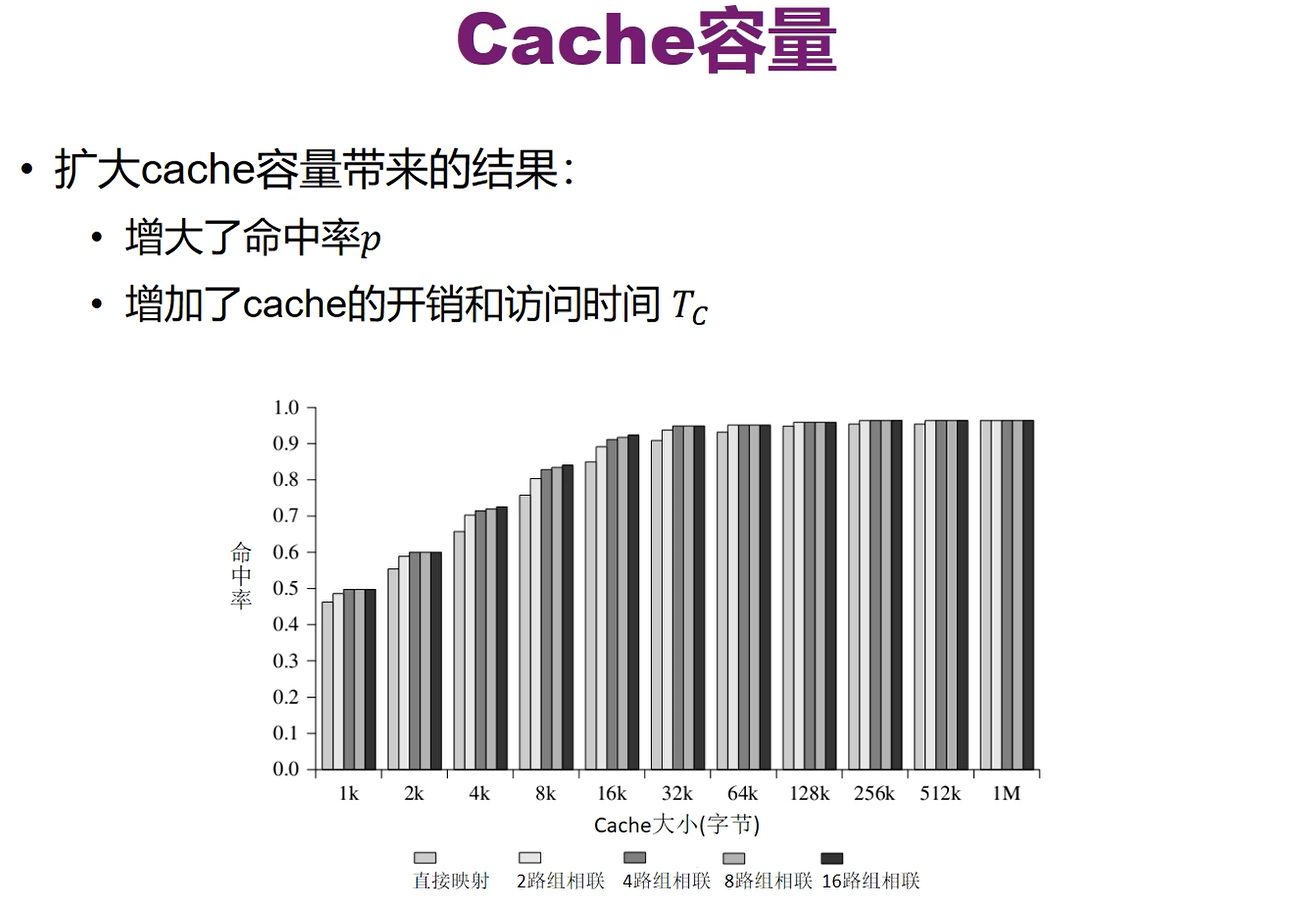
cache容量不是越大越好,也不是越小越好。
- 因为内存是以地址来寻找的,所以直接解码地址就能找到要的信息,而cache则是通过遍历来找的(遍历块的标号),所以如果cache很大的话,会导致遍历检查的时间增加,增大了Tc。
- 如果cache很小的话,则可能出现从内存中复制的新的块把原来cache中的块覆盖后,又需要原来的块中的内容,因此又需要从内存中复制到cache,浪费时间
二、映射功能

cache中记录的是块号,块号要能反映地址
块内地址:如果一个块内有K个字节,那么地址的后log2K位表示块内地址
而cache中分辨不同块的标记可以直接使用块号来作为标记,但这样会造成一些浪费(块号不是我们想要的信息),因此就要去想怎么尽可能缩短标记的长度
1.直接映射

比如0~7块只能放到第一行,8~15块只能放到第二行,因此如果加载了第2个块,想再加载第3个块,那么第3个块会把第二个覆盖
如上图i=jmodCi=jmodCi=jmodC是间隔的把块规定放到同一行,而不是上面的连续的几个块都只能在一个行中,显然下面这种更合理,因为局部性原理,访问相邻块的概率更大,因此间隔的放,可以把连续的块都加载到cache中,而不会出现上面的覆盖情况
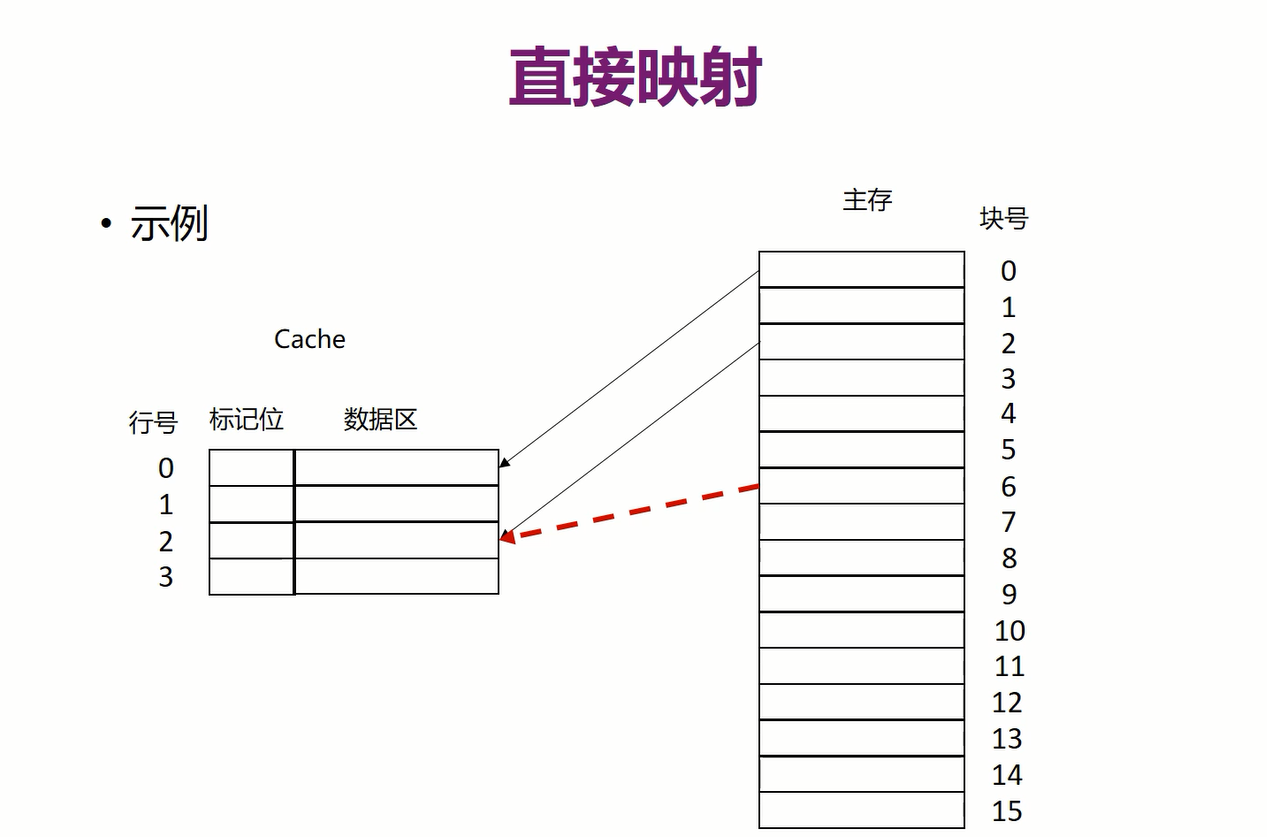
映射到同一行的块号(二进制表示)的后log2Clog_2Clog2C位都是一样的
因此只要比较块号的前面log2M−log2Clog_2M-log_2Clog2M−log2C位即可(M是块的数量,C是cache中行的数量)相当于把C个块当作一个组,只要记录这个组的地址即可

再看主存中一个具体的字节,它在主存的地址可以被分成三个部分:
- 块内地址(用于块内寻址)
- 块映射到cache的行号
- 若干个块分为一个组对应的标号,用于区分映射到相同行的不同块,记录为cache标号

- 优点:因为块映射到cache中的行的位置是固定的,因此检查时,只要去找这一行中有没有要的数据即可,而不必全部搜索一遍,所以Tc是固定的,不会因cache容量增大而使得Tc变大
- 缺点:抖动现象:如果要重复访问的两个块刚好映射到同一行,就会降低命中率,当两个块比较相邻(才可能被重复访问)时并被映射到同一行,说明cache比较小,即行数比较少时会出现这种情况。
- 因此直接映射适合大容量cache使用
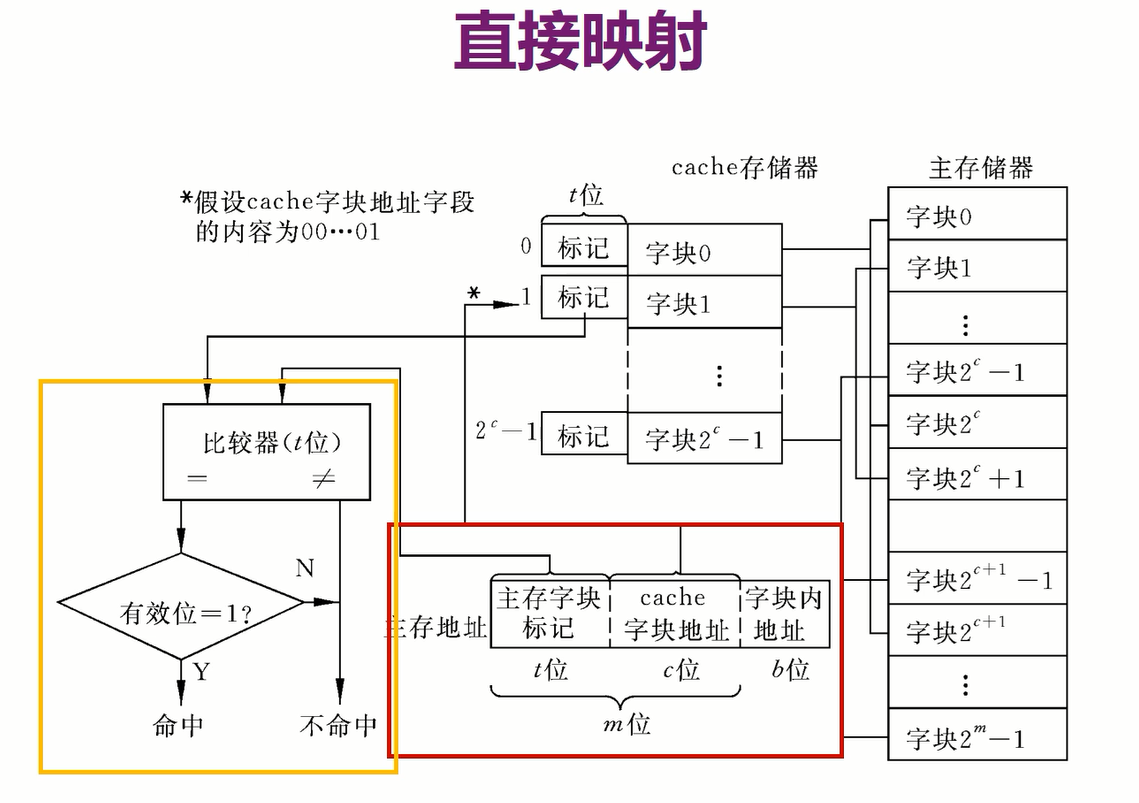
- 根据内存地址的块地址去找cache对应行
- 再比较cache标记和主存地址的块标记是否相等
- 相等就命中,命中就再根据主存地址的块内地址到cache取对应字节
2.关联映射
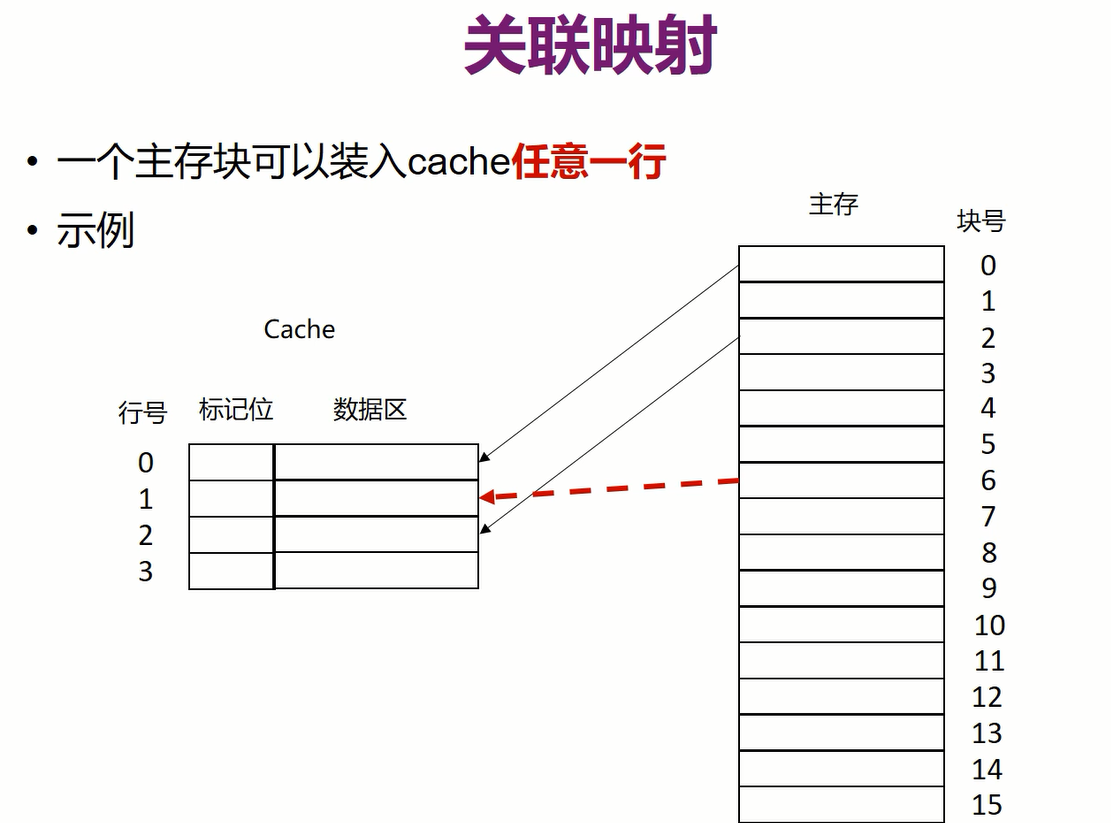
关联映射中的标记必须是块号,所以长度只能是log2Mlog_2Mlog2M,不像直接映射中有规律,可以缩短。关联映射是可以按一定规则放的,只要有空位就能放


- 优点:在cache比较小时不会出现抖动,想加载哪些块都可,不会出现反复加载,除非cache行数不够了
- 缺点:怎么规定放块实现比较复杂,同时检查时要平均检查12\frac{1}{2}21的cache,在cache很大时开销太大
- 因此关联映射适合容量小的cache
3.组关联映射(介于前面两种方法之间)

K是指每组里面包含的行数,S是组数
即将cache分成不同的组,一个块只能映射到对应的组中,但在这个组中可以放在任意一行
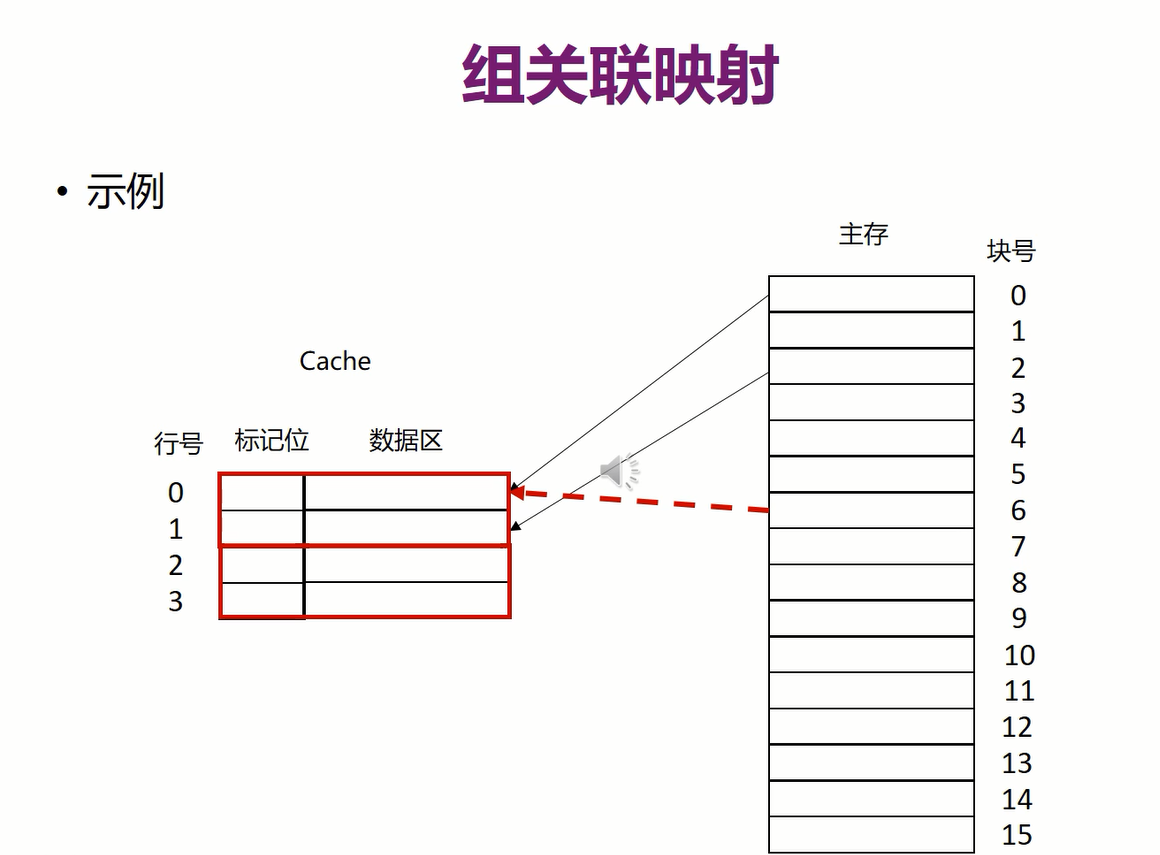

标记中不需要存全部块号,因为组号是固定的,只要log2M−log2Slog_2M-log_2Slog2M−log2S位即可



**关联度:**一个块映射到cache中可能存放的位置个数
关联度越低,命中率越低,检查是否命中的时间越短,标记所占的额外空间开销越小
三、替换算法
目的:将最不可能被使用的行替换掉,尽可能增大命中率
替换算法使用硬件来实现,因为替换需要非常快的速度


1.最近最少使用算法(LRU)
假设前提相当于看文件被修改过到现在的时间

需要限定路的数目,多路会很复杂,在模拟中可以通过设置时间戳的方式来记录最近使用的时间,要替换时最早的那个就是最近最少使用的
2.先进先出算法(FIFO)
假设前提相当于看文件被创建到现在的时间

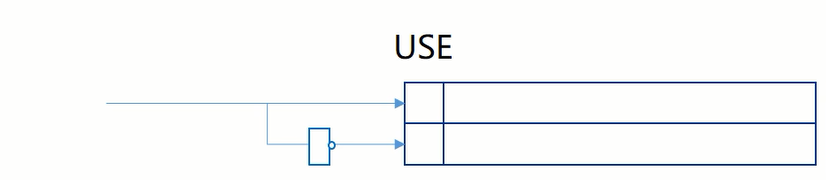
无需限定路的数目,只要循环轮下来即可
最开始初始化是应该把每一行的use位设为0,因为相当于替换哪行都可以。
替换时把被替换的行设为1,把它的下一行设为0(如果是最开始,那么它的下一行本来就是0),如果被替换的是最后一行,那么把第一行设为0,这样循环,可以保证一个组中至少存在一个use位为0的行,从而用新数据去替换这一行
3.最不经常使用算法(LFU)

4.随机替换算法(Random)
能到cache中的的块都是使用率较高的,否则不会进到cache中,所以不再去区分cache中块的使用率

性能只比其他区分cache中块优先级的差一点点,但实现起来相对简单很多
四、写策略
写数据时,CPU同样会优先修改cache中的数据

对cache的修改不需要直接同步到内存中,因为之后CPU读的还是cache中的内容,因此只要存在cache中即可;只有在cache中这个块要被替换时,才要把修改同步到内存,否则这个修改就丢失了
1.写直达

对于多CPU共享一个内存的情况,实时同步数据是必要的
2.写回法

缺点就是如果这个块被修改但没有被替换,那么它不会写回主存同步修改,而I/O模块对主存如打印时就得不到最新的数据了,只能增加设计:在打印时把所有cache中脏位为1的都同步到主存
五、行大小

六、cache数目

L2容量比L1更大,L2从内存中取了数据,L1从L2中取了数据,同样找数据时也是先在L1中找,如果未命中,再去L2中找
为什么不只使用大容量的L2,而是加入了L1?

分立:对指令和数据分别用不同的cache
总结

)]
L2容量比L1更大,L2从内存中取了数据,L1从L2中取了数据,同样找数据时也是先在L1中找,如果未命中,再去L2中找
为什么不只使用大容量的L2,而是加入了L1?
[外链图片转存中…(img-Pa7XGQ10-1656554789633)]
分立:对指令和数据分别用不同的cache
总结
[外链图片转存中…(img-5w3yeJG8-1656554789635)]