论文原文地址GitHub论文源码下载
0. XLNet概述
XLNet是一个语言模型。和ELMO,GPT,BERT一脉相承,同时借鉴了Transformer-XL,故称XLNet(XL含义源于衣服尺码,意思是模型横向更宽);并提出一些新方法改善了Bert存在的问题,目前取得了全面超越Bert的成果。和Bert一样,XLNet也分为Pre-train和Fine-tune两阶段;并且参数规模比Bert更大。
1. AR(autoregressive) vs AE(autoencoding)
AR译为自回归,意思是对于序列 ,根据
预测
。GPT,ELMO都属于AR语言模型。
AE译为自编码,意思是将序列 编码为
。Bert属于AE语言模型。
AR的缺点在于序列要么从前往后,要么从后往前,无法将上文和下文信息完全结合起来(ELMO只是将两个方向concat)。AE模型的缺点在于Pre-train阶段可能需要引入 标记(Bert模型),而
会带来一系列问题。
2. Bert的痛点
得益于同时使用上文和下文信息,Bert取得了比GPT更好的效果。但是Bert需为此在Pre-train阶段引入 标记,通过上下文来预测这些被mask的token。
引入 标记带来一下两个问题:
2.1 独立性假设:Bert假设不同[mask]相互独立,忽略了[mask]之间的相关性
设被mask的token集合为 ,整个序列为
,Bert的训练目标是最大化联合概率分布
。在计算此概率分布的过程中,Bert会假设所有被mask的token(
中的token)相互之间都是独立的,这样就丢失了不同masked token之间的关联。
论文中举了一例,现有序列 ,
Bert如果随机选择了 和
进行mask并预测,则mask后序列变为
此时应该优化的目标是:
但实际上bert的优化目标是:
若要满足 , 则有
即New和York相互独立。但显然它们不太独立,如果前面出现了“New”,那么后面出现“York”的概率理应大很多。
2.2 Pre-train阶段和Fine-tune阶段数据分布不一致
Bert在Pre-train阶段需要对语料使用 标记;但在Fine-tune阶段,所用语料中并没有
标记。这导致两个阶段的训练数据分布不一致,影响Fine-tune效果。
3. XLNet如何解决bert的缺陷
如果有一种模型,既能结合上文和下文,又能避免bert由于 导致的独立性和数据分布一致性问题,就两全其美了。为此,XLNet使用一系列方法,构造出了一种能够结合上文和下文的AR模型。
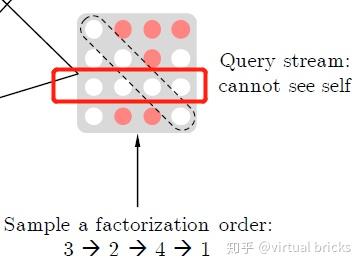
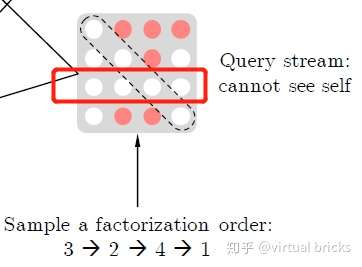
排列组合获取上下文信息
为了在不改变AR模型基本结构的条件下引入下文信息,XLNet使用了对输入序列“排列组合”的方法,把下文信息排到前面,赋予了单向模型感知下文的能力。例如,现有序列 ,只需改变其顺序,变换出
、
、
等序列,即可让3看到4,2看到3和4,1看到2、3、4。下图为不同排列方式下,位置"3"所能关注的位置示意图(只能关注序列中在它之前的部分):
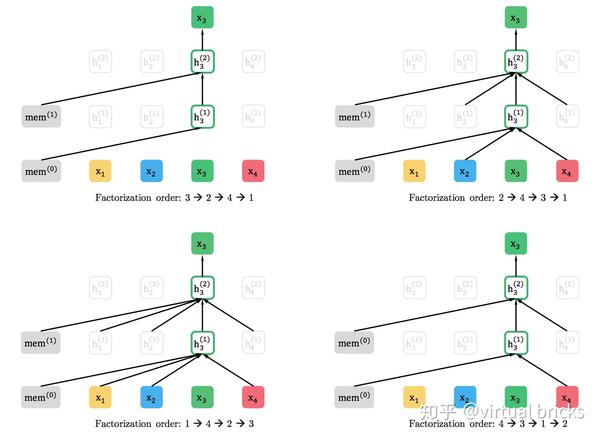
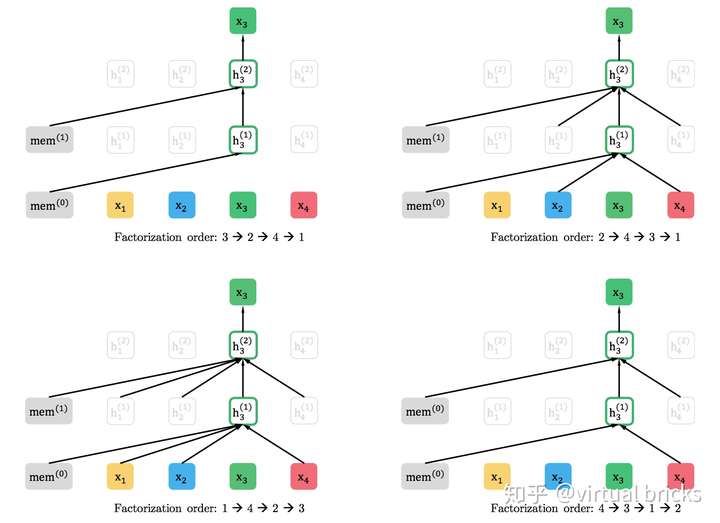
将上述过程形式化,设 为长度为
的序列
的所有可能的排列,
为其中一种排列方式,
,
为第其中
个元素,
为前
个元素。优化目标为 :
仍以序列 为例:
这样,任何一个元素都可因排列组合方式的变换而成为序列最后一个元素 ,从而能够看到所有上下文信息。
注意,排列组合并不是真的使用原始序列生成新的排列组合序列,并抽样产生新的增强数据集来完成的,因为这种做法仍然会造成Pre-train和Fine-tune的语料分布不一致。XLNet的做法是在计算attention时mask掉对应位置,不同的mask对应不同的序列。后文将详述此法。
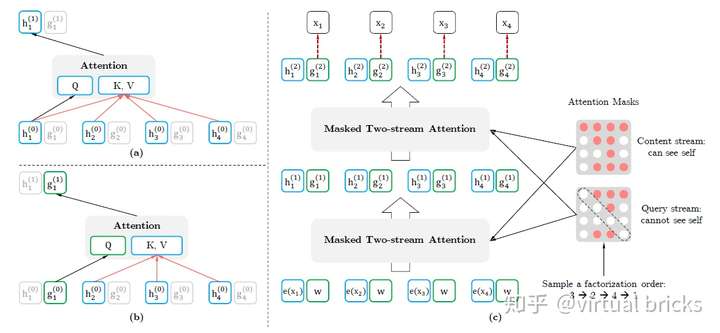
双流注意力
上述模型中,设 为
的hidden表示,则使用softmax计算next-token的分布时有:
由上式可知计算目标概率分布时, 根本没有出现,这就丢失了
代表的原始序列中位置的信息。也就是说
处于句子任何位置都一样。
形式化表述,设 ,但是
,
此时有 ,(原文此公式应该是有小笔误,将一个2写成1)显然和ground-truth冲突。
举个例子,有序列 [暴雨,造成,大面积,晚点] ,产生排列组合序列 [暴雨,造成,大面积] 和 [暴雨,造成,晚点] , 则 就是共同的前置序列 [暴雨,造成],
就是"大面积",
就是"晚点"。它们
相等,也就是"大面积"和"晚点"出现的概率等价,不合逻辑。
注意,即使像Bert那样在输入中加入位置向量,仍无法避免 处位置信息缺失,原因如下图:
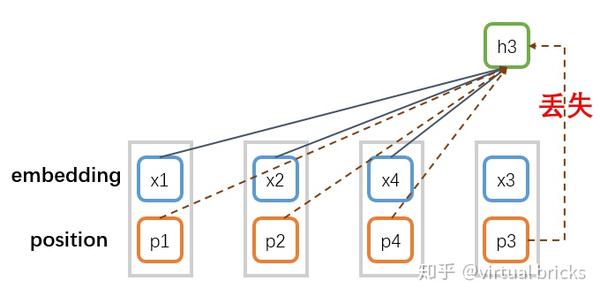
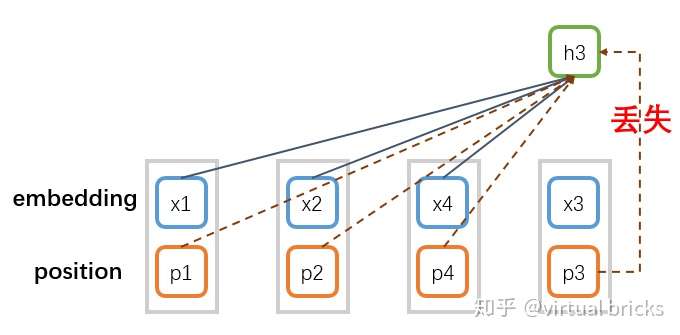
要解决这个问题,就必须引入位置信息 ,然后将
变为
,调整后的概率分布的计算公式如下:
XLnet为 和
分别开辟一条attention流。因此称为双流attention。论文中给出的原理图示如下:
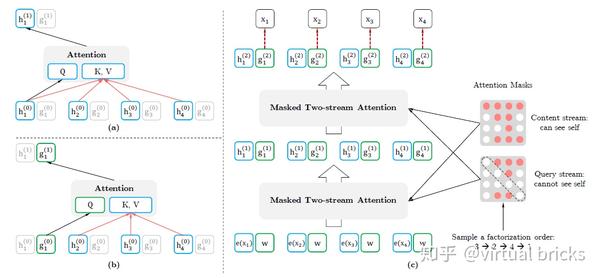
和
的计算公式如下:
注意,一个是 ,一个是
。在
中,m代表编码器层数,
,
。
是随机初始化的向量(位置向量?),
是随机初始化的词向量。
另外,你可能会发现在计算 时,由于
,
为空。如下图:
难道这时候所有attention权重都为0, 计算出来也是0向量?当然不是。因为XLNet还有memory机制和残差连接(与transformer编码器相同),保证
不是0向量。
4. XLNet如何降低训练开销
用了“排列组合”技术后,理论上每个原始序列的每种排列组合序列里的每一个位置 都可以作为target来训练。但是这样搞训练开销太大,毕竟Bert只在更少的语料上挑了原始序列中15%的位置,普通玩家就已经玩不转了。XLNet的解决办法是只把一部分位置作为target进行训练,那么如何选取这一部分位置呢?XLNet这里是把一个序列
划分为两段,只对后一段进行训练。
例如 只训练3和4,不训练1和2。
具体地,就是取一个位置 , 满足
,
不作为target,
作为target进行训练。关于
值的选取,作者给出了一个超参
,满足
,作者设置
。
优化目标变为:
5. Transformer-XL与memory
在实际应用中,遇到超长序列(篇章,对话等),通常需要拆成sentence级别的短序列,这样割裂了短序列之间的联系。对于这个问题,Transformer-XL的做法是把上一个短序列各层输入的一部分作为memory缓存,和当前各层的输入拼接,以获取上文的信息。
具体地,设长序列为 ,分为前序列
,后序列
。加入memory机制后,
的计算公式变为:
attention mask也变为如下模样(自己理解的,可能有误):
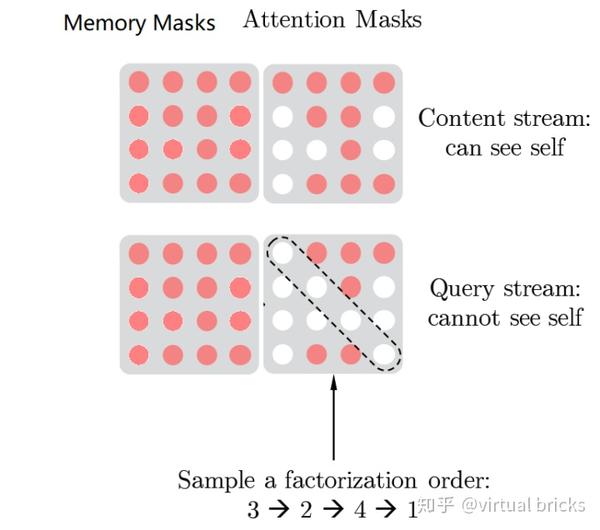
事实上,XLNet并不将整个 放入memory,而是截取其中一部分。根据论文列出的超参,序列长度最大为512,memory最大长度为384。
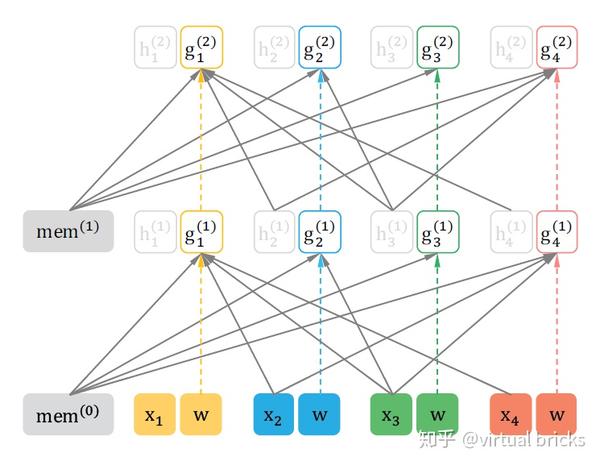
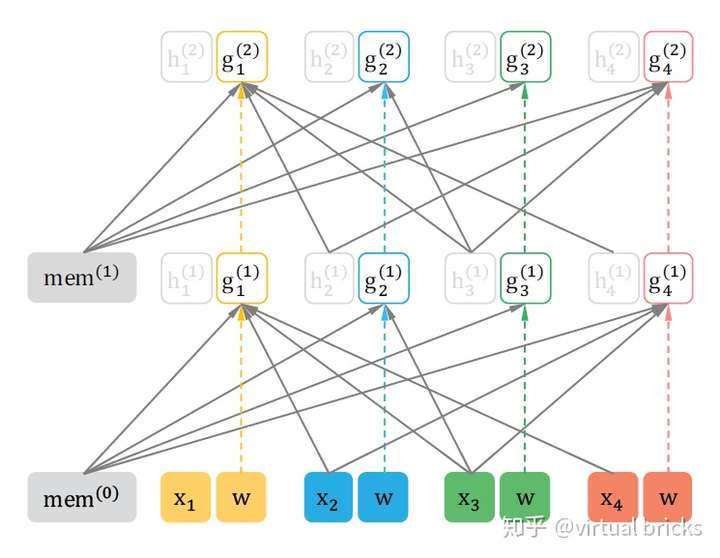
6. 整体计算过程
XLNet和transformer一样,每层都要加入前馈连接,层归一化,以及前馈网络。
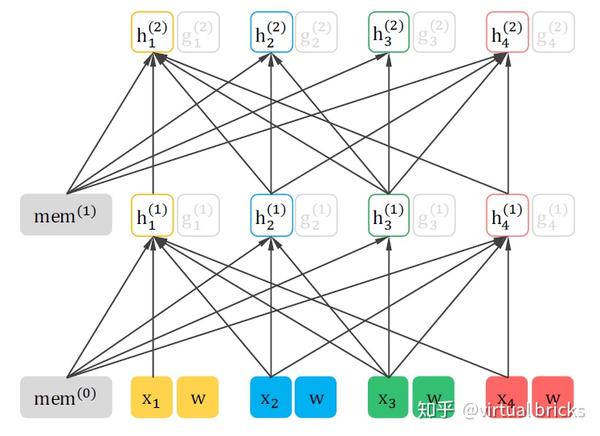
对
下图为 和
的整体注意力计算示意图:
7. 总结
XLNet这篇paper中,排列组合序列,双流注意力,memory机制都是非常值得学习和借鉴的思路。但是在模型越来越大的趋势下,自己动手pre-train已经不可能。只有坐等大厂放出基于中文语料pre-train的模型了。
目前依然有一些细节,在论文中没有明确体现。例如:
排列组合模式如何采样
对一个原始序列的排列组合有 种,不可能全都都用。如何对排列组合进行采样,文中没有具体说。
memory的实现细节
memory的实现细节(如何mask)还需推敲,需要研读源码以及transformer-XL论文