20220324
1.取数逻辑修改以及跨年取数问题的处理 2
2.特征构建和特征工程 4
3.模型训练,测试,评估 3
4.数据写入数据库,代码规范化、文档修改、部署、调度 1
流失预测更新计划
三个时间点 假设间隔为1个月
1 2 3
2月和3月之间判断在3月当前的时候是否为流失也就是上一期
也同时是训练数据的真实标签部分,所以就计算出可能涉及跨年的1和2个日期点
根据离当前年1月1日的日期差是否小于间隔来判断
20220323
1.滚动预测没有必要,增加一天或者一周的数据可能会使结果波动很大,效果会很难看
2.异常时间比如119和过年时间的去除或者直接去掉所在月
3.流失是长时间流失比如一个月或者两个月 而不是关注于周或天的波动
4.按客户分类查看结果会发现问题比较大
5.打标标签可以不叫做流失就叫做未来某段时间是否会流失就可以了
6.因为我们周末不上班,相当于周末客户基本不采购 所以变化量会很大
更新迭代要做的事所需耗费的时间
1.研究的时间
2.取数方式的更改
3…新指标的计算
4.滚动预测的修改
5. 乘以1.3
20220318
一款社交应用,通过流失用户的特征分析。发现了如下的几个特点。
流失用户中,40%的用户没有完善资料
新增用户没有导入通讯录好友,流失概率比导入的高20%
新增用户在第一周使用中,如果添加的好友低于3,则一个月后的流失概率超过一半
用户流失前一个月,互动率远低于APP平均值。
可以再考虑的指标
尝试更改流失阈值看准确率情况 比如输出概率超过80%才预测为流失
20220215
1.产品关注及时性 这个问题不存在
2. 可解释性 看图标解释
20220126
特征改进
1.增强其他客户行为特征
2.可能本身无法再提高,因为打标本身就不能保证完全正确
3.过去60天的特征和预测目标同时间长度段的特征
4.增加lag期数
5.增加指标方差
6.增加其他行为特征
7.增加去年同期的指标情况
20220119
同事可借鉴之处
沉默天数
订单天数
订单数量
这价格指标历史窗口的求和,平均,方差,最大,最小 (这个最重要)
订单金额 :原价金额,订单优惠,毛利润
订单间隔: 商品数量 品名,一级,二级,三级
注册天数
地址
类型
20220118
加入RFM特征
加入滞后一阶目标变量的值
加入最后一次购买的月份(周期特征)
改进:扩展滞后多阶(最近多次)
药品具体种类数量改成,药品类目数量
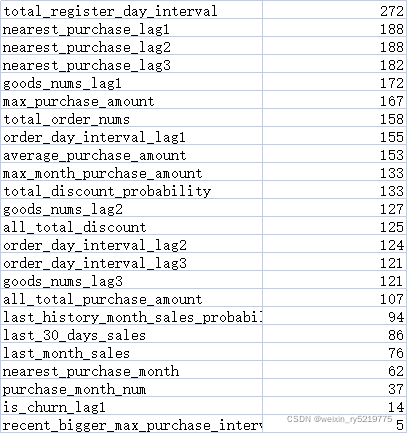
20220109
训练集和测试的划分标准
训练集里面不要包含测试集的数据?
训练集或者测试集不能包含未来的数据
测试集中的新数据要足够丰富可信
流失预测 最好以流失间隔70天为训练和测试的划分?
20220108
训练是用所有的用户数据,预测的时候只需对有价值的客户进行预测
RFM最好用历史所有的数据?
http://www.woshipm.com/pmd/338242.html
别走!没有想到你是这样的用户!——流失用户预警
流失加上生命周期,是在那个生命周期的流失
20220105
1.流失的定义
1.1 对象范围的确定
只对高或者高中价值客户进行预警
RFM作为判定依据,取12个月 (消费频率是客户在固定时间内的购买次数(一般是1年))
(因为RFM与时间有关,因此很多同学在取数的时候会纠结时间怎么分。严格来说,越柴米油盐,消费频次本身越高的业务,取的时间应该越短。)
最典型的就是生鲜,人天天都要吃饭,7天不来可能就有问题。普通的快消品零售可能取30天,类似服装百货零售可能取90天。当然,更多的做法是按月取。)
用户生命周期如何确定?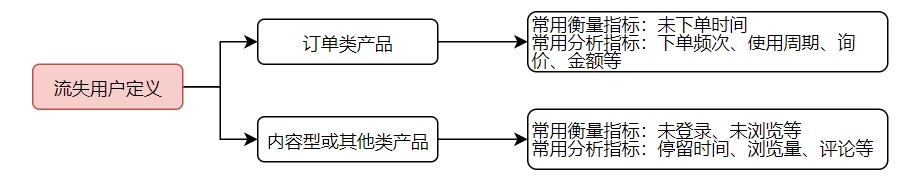
1.1 流失时间(周期)的统计比如可以取过去半年以来用户的数据作为样本,由于用户是否流失结果已知,可以给用户打上流失概率的标签,观察期也就是训练样本所取时间范围,表现期对应从测试1.2 流失动作的确定量化的核心逻辑,是挖掘出不同时间范围用户,在此后一段时间的回购率分布。预期复购时间通过统计所有客户两次采购之间相关时间间隔的分布情况(极端情况要去除)来做决定 未完成区间的界定有一定灵活性,回购分析区间的时间要尽量覆盖锚点前用户的预期复购时间,不能太短,一般会在3个月以上。假设案例中的品牌消耗周期较长,有大促囤货心智,所以回购分析区间长度是一年。
https://mp.weixin.qq.com/s/3_jXRqn8cgLg6lymX_ijcA
打标流失客户的时候,定的时间尽量长,预测的时候并不会用到这个指标标准
1.3 流失客户和RFM周期的时间如何统一?
流失客户定义标准确定之后,实际上用的时候锚点设为程序运行的当天
流失客户的时间段定了之后,其实RFM的时间段也是这个相当于一个用户周期了
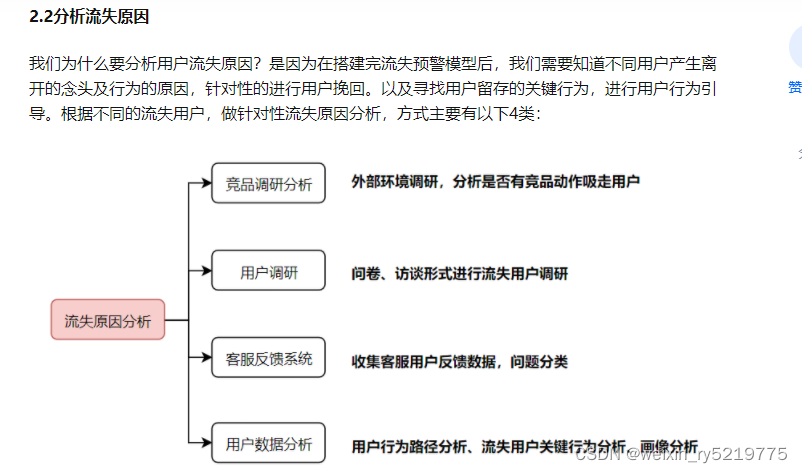
2.具体是什么原因导致的流失?并如何形成特征体现在模型中?
2.1 自愿和非自愿
3.预测阶段的处理 这里采用自身的情况
3.1客户分层。在实际处理过程中,客户流失时间较长(三个月以上)的基本不会回归,因此针对客户流失天数对客户进行分层,本例中分为三层90天以上、45-90天及45天以下,90天以上不做预测,分别对45-90与45-进行预测,准确率分别为91%与74%
3.2进一步分析。在45天以下的客户里面,现有指标已无法对其进行细分,经与领导沟通,对其中部分客户进行回访调查不消费原因,相当一部分客户的业务具有周期性,通常为30天或者半月,分析历史连续不消费天数可印证这一点,另外一部分客户数据量很少,难以区分。因此剔除数据量较少客户(取历史消费天数大于30天),最终预测准确率为86%
以上所有指标除客户基本信息外均为反推客户三个月前状态(也就是确定的最长流失时间)
取这个时间之前的所有数据进行训练,剩下的数据进行验证
4.预测出了流失客户,.后续的挽回客户的策略(不归我们管)
5. 需要划分活跃和非活跃吗,其实就是RFM的划分
6.用户浏览的数据有吗? 没有,登录的数据是有的
7.什么时候上禅道?
问题再次重新整理
所以流失用户是指持续未使用的用户,所以监控的时候,我们也是看持续时间内没有使用的用户,所以这条曲线永远是一个下降的曲线,因为在监控的持续时间内,只要有使用行为,会被记为留存用户(除去活跃用户和流失用户就是留存用户,比方说一个产品,用户30天内每天使用就是活跃用户,30天内没有一天使用就是流失用户,那30天内使用一次、两次等次数的用户就是留存用户)
https://zhuanlan.zhihu.com/p/40828409#:~:text=%E4%B8%8D%E5%90%8C%E7%9A%84%E4%BA%A7%E5%93%81%E6%9C%89%E4%B8%8D%E5%90%8C,%E9%83%BD%E7%94%A8%E7%9B%B8%E5%90%8C%E7%9A%84%E9%80%BB%E8%BE%91%E3%80%82
1.流失预警的目标是通过特定算法分析出哪些客户
具有较大的流失概率, 从而对这些客户进行有目的、有
区别的挽留工作, 尽量减少客户流失带来的损失
其中自愿的、非财务原因的流失客户往往是高
价值的、稳定的客户。他们会正常的支付自己的服务费
用, 并对市场活动有所响应。所以这种客户才是电信企
业真正想保持的客户。而真正在分析客户流失的状况
时, 还必须区分公司客户与个人客户, 不同服务的贡献
率, 或者是不同客户消费水平流失标准的不同
实际上, 成熟的电信行业客户
流失分析经常是根据相对指标判别客户流失。
研究发现, 客户的流失行为虽然是突发的, 但流失前
大部分客户原本稳定的话务行为会出现一定程度上的
异动, 譬如出现交际圈缩小, 通话量激剧下降等,
常规思路一般按照客户流失考核指标( 不出
账则流失) 做目标变量, 但这已经处于客户生命周期的
晚期, 挽留难度大。本研究尝试将时间点提前, 从客户价
值角度分析客户的生命周期, 将目标变量定义在客户价
值的急剧下降(Sharp_Decrease) 时期[ 1]。
客户价值定义: 本文定义的客户价值主要包含客户
通话, 因为收入的产生基于客户的消费行为( 目前主要
考虑是通话), 而且从之前的宏观角度看, 这些行为更有
规律性, 具备数据挖掘分析的前提。
流失客户: 是指本月有通话, 而在之后两个月通话次数小于15 次,
并且在之后两个月通话平均降幅大于60%的客户。
通常指客户转移到竞争对手享
受服务。显然第二种流失的客户才是电信企业真正关心
的, 是对企业具有挽留价值的客户。因此, 在选择建模数
据时必须选择第二种流失的客户数据参与建模, 才能建
立出较精确的模型[ 3]。 重点
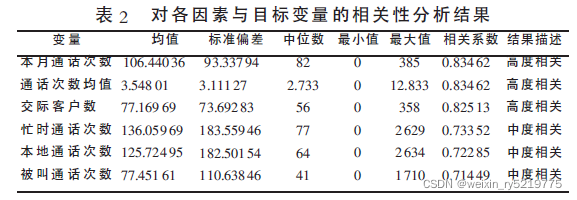
相关性分析特征
方差分析是利用样本数据检验待选指标对目标总
体影响程度的一种方法。目标总体差异的产生来自两个
方面, 一方面由总体组间方差造成, 即指标的不同水平
(值)对结果的影响;另一方面由总体组内方差造成, 即指
标的同一水平(值)内部随机误差对结果的影响。如果某
指标对目标总体结果没有影响,则组内方差与组间方差
近似相等; 而如果指标对目标总体结果有显著影响, 则
组间方差大于组内方差。当组间方差与组内方差的比值
达到一定程度, 或者说达到某个临界点时, 就可做出待
选指标对结果影响显著的判断[ 6]。
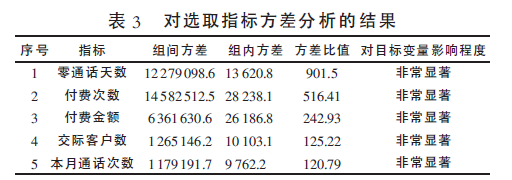
方差分析
数据挖掘技术在电信客户流失预警系统中的研究_2.pdf 框架重点
20220104
https://github.com/tonysjohn/e-Commerce_Customer_Churn
e-Commerce
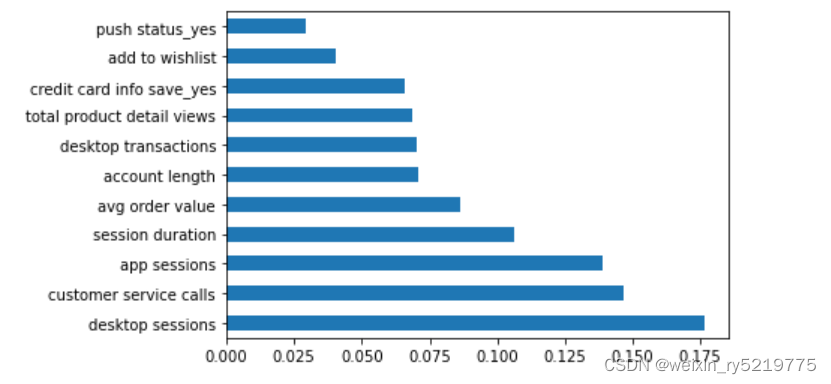
Features Importance
nb_active_months 0.177715
nb_days_last_activity 0.121025
nb_visits 0.102029
nb_distinct_category1 0.058217
nb_days_last_purchase 0.05582
nb__distinct_products 0.05526
amount_purchase 0.054337
amount_purchase_total 0.046802
nb_products_seen 0.036346
nb_associated_months 0.035496
重点 nb=number
nb_visits : Number of user activity
nb_purchase : Number of user purchases
amount_purchase : Amount purchased
nb_products_seen : Number of products seen by user
nb__distinct_products : number of distinct products seen by user
nb_distinct_category0 : number of distinct categories seen by user
nb_distinct_category1 : number of distinct sub-categories seen by user
nb_distinct_category2 : number of distinct sub-categories seen by user
nb_distinct_product_purchased : number of distinct products purchased by user
nb_distinct_category_purchased : number of distinct categories purchased by user
Trend Activity features : These features are created from aggregating user activity for the most recent time period(say 1 months). These features capture the trend of user activity in the recent past. This involves data about the number of visits, number of purchases, total purchase amount etc.
The features are same as the Basic Activity Features but with a limited scope.
Global Activity features : These features are created from aggregating user activity for the entire association with the website. It captures the overall activity of the user from the start.
Find below the complete list of features:
nb_associated_months : Number of months between first activity and Evaluation date
nb_days_last_activity : Number of days from last activity
nb_days_last_purchase : Number of days from last puchase
nb_active_months : Number of months with active vists to site
nb_active_purchase_months : Number of months with purchases in site
nb_purchase_total : Number of purchases for entire user activity
amount_purchase_total : Total purchase amount for entire user activity
https://github.com/fgurkanli/A-Case-Study-on-Customer-Churn-Prediction/blob/main/fgurkanli_case_study.ipynb
 特征重要度
特征重要度
https://github.com/nprihandina/ecommerce_churn_prediction
ecommerce_churn_prediction
重点
https://github.com/ChromaticFire/B2B_Platform_Customer_Churn_Model
大宗商品B2B电商平台客户流失模型-
Feature Name Importance
Number of orders 0.206
Standard deviation of the order dates 0.115
Number of session in the last quarter 0.114
Country 0.064
Number of items from new collection 0.055
Number of items kept 0.049
Net sales 0.039
Days between €rst and last session 0.039
Number of sessions 0.035
Customer tenure 0.033
Total number of items ordered 0.025
Days since last order 0.021
Days since last session 0.019
Standard deviation of the session dates 0.018
Orders in last quarter 0.016
Age 0.014
Average date of order 0.009
Total ordered value 0.008
Number of products viewed 0.007
Days since €rst order in last year 0.006
Average session date 0.006
Number of sessions in previous quarter 0.005
https://www.connectedpapers.com/main/ebb7913b5c5bf1ce3b8aef8d0a4d2f0a704ba7a2/Customer-Lifetime-Value-Prediction-Using-Embeddings/graph
Customer Lifetime Value Prediction Using Embeddings
https://github.com/xiaogp/customer_churn_prediction
customer_churn_prediction
https://github.com/fundoop/customerlosing_prediction
客户流失预测
重点
1、特征的构建与选取。现有指标包括客户基本信息(身份证号、注册地址、车辆信息,身份证号可解析出出生日期、性别、省份)客户总消费、消费天数、逾期金额、逾期次数、历史最大及最小连续消费天数、历史最大连续不消费天数、近一月消费额等。
2、模型搭建。接口序贯(Sequential)模型。第一层全连接层,激活函数选取relu;第二隐层全连接层,激活函数选取softsign;输出层激活函数选取sigmoid。损失函数选取binary_crossentropy,激活函数选取adam,学习率为默认值。
3、模型运行与调优。初次运行验证集准确率较低,通过调整激活函数及加入Dropout层,得到76%准确率
4、特征引申及筛选。引申指标包括当前不消费天数是否大于历史最大连续不消费天数、近一月消费额与历史最大30天内消费额的比例、客户历史最大连续逾期天数等。通过主成分分析法剔除关联度较低的指标。提高准确率到96%。
5、客户分层。在实际处理过程中,客户流失时间较长(三个月以上)的基本不会回归,因此针对客户流失天数对客户进行分层,本例中分为三层90天以上、45-90天及45天以下,90天以上不做预测,分别对45-90与45-进行预测,准确率分别为91%与74%
6、进一步分析。在45天以下的客户里面,现有指标已无法对其进行细分,经与领导沟通,对其中部分客户进行回访调查不消费原因,相当一部分客户的业务具有周期性,通常为30天或者半月,分析历史连续不消费天数可印证这一点,另外一部分客户数据量很少,难以区分。因此剔除数据量较少客户(取历史消费天数大于30天),最终预测准确率为86%以上所有指标除客户基本信息外均为反推客户三个月前状态
https://github.com/ZhichenSong/-/blob/master/%E5%AE%A2%E6%88%B7%E6%B5%81%E5%A4%B1%E5%88%86%E6%9E%90_V3.ipynb
酒店预订
重点
特征 备注 特征 备注
shop_duration 购物时间跨度
recent 6个月R值
monetary 6个月M值
max_amount 6个月最大一次购物金额
items_count 总购买商品数
valid_points_sum 有效积分数
CHANNEL_NUM_ID 注册渠道
member_day 会员年限
VIP_TYPE_NUM_ID 会员卡等级frequence 6个月F值
avg_amount 客单价 i
tem_count_turn 单次购买商品数
avg_piece_amount 单品购买价格
monetary3 3个月M值
max_amount3 3个月最大一次购物金额items_count3 3个月购买总商品数
frequence3 3个月F值
shops_count 跨门店购买数
promote_percent 促销购买比例
wxapp_diff 微信小程序购买R值
store_diff 门店购买R值
shop_channel 购物渠道
week_percent 周末购物比例infant_group 母婴客群
water_product_group 水产客群 meat_group 肉禽客群
beauty_group 美妆客群 health_group 保健客群
fruits_group 水果客群 vegetables_group 蔬菜客群
pets_group 家有宠物 snacks_group 零食客群
smoke_group 烟民 milk_group 奶制品客群
instant_group 方便食品客群 grain_group 粮油食品客群
https://github.com/xiaogp/customer_churn_prediction/blob/master/README.md
零售电商客户流失模型,
打标和预测是分开的,利用规则打标
但是预测是相对于还没满足打标流失条件时候进行的预测和提前预警
建模的意义 重点
存活率
https://mp.weixin.qq.com/s/XthPYKp-HpdHNz0HgKO_sw
运营|流失用户召回策略,再不看来不及了
https://mp.weixin.qq.com/s/nfmQWNjM4jueci0Z5xF0TA
浅谈互联网金融产品“预流失用户”的定义
基于数据挖掘技术的客户流失预警模型 论文
我们将流失客户的具体定义为:上月有通话和出帐记录,但经过预测,下个月将不会产生通话或出帐记录的客户
重点
http://www.woshipm.com/data-analysis/1054899.html
查全率
客户流失预测模型,如何进行效果评估
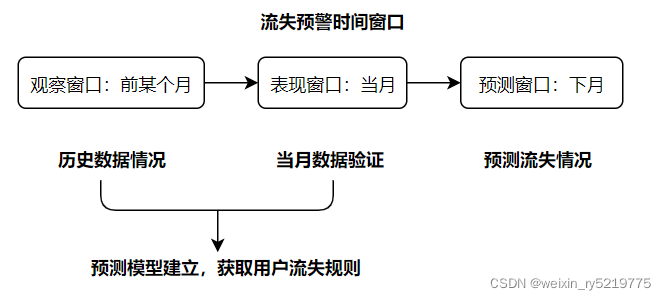
https://zhuanlan.zhihu.com/p/145572623
讲讲用户的流失预警
需要处理的问题
1.是否符合当前需求,目标是什么 在未达到流失标准之前进行预测
2.需要知道具体是什么原因导致的流失吗?
3. 需要作为特征体现在模型中吗?
4.流失用户的定义,
时间周期如何定,正样本如何打标
电商未下单的时间长度
5.特征,指标
一般来说,我们需要考虑的特征可能有以下几个类别:
用户的基本属性:性别,年龄,收入水平,区域等,不同类型的用户可能流失也有所区别
具体到合纵:客户类型,
5.1.是所有产品都不买了吗,
5.2.还是只是部分(流失定义应该是购买的药品种类数减少的幅度)重点
5.3.下单频次可用,下单金额应该没什么用
5.4 选择特征
原则:所选取的特征,应该跟流失与否有关联!
活跃属性
消费属性
最后距今登录天数
最后距今购买天数
事件属性(好评、中评、差评)
https://blog.csdn.net/u010271601/article/details/104485031/用户的产品行为:所处产品的生命周期,活跃的频次,关键功能的使用频次等,这些我们称之为基础指标,基础指标一般是流失原因的表象,和流失具有相关性,但不具备因果性,不是导致流失的关键特征
其他加工指标:基础指标可能不能很好的挖掘到影响留存的关键特征,需要基于业务理解加工出新的指标,和基础指标一起作为模型训练的特征。常见的加工方法有:
5.5浏览多,但是下单少,甚至不下单,极有可能只是比较 预示着要流失深度指标:反应用户使用深度的指标,用户不仅要用,而且要用的比较深入,比如关键功能的使用次数,有的用户可能只是用了一些边缘性的功能,还未接触到关键功能就流失了,这是很可惜的,所以用这个深度指标可以预测用户是否可能流失的。频次指标:用户不仅要用的深,还要用的频繁,这个频繁的定义依据不同的产品类型而有不同的定义,有的产品可能需要每天都要用,甚至一天要用几次,有的可能要求一周要用几次,不一而足。但是可以根据产品的特点加工出一个频次指标,比如日/周均使用次数或者日/周均使用天数,这样用户的使用频次得以表征。5.6什么样的频次,登陆的频次,下单的频次趋势指标:用户使用产品的趋势变化,用户使用的趋势直接关系着用户的流失,如果一个用户使用的越来越少了,那大概率用户是要流失了,所以一些常见的趋势指标如近三个月每周平均活跃天数的变化率,可以理解为一个斜率,如果每周的平均活跃天数在一直减少,斜率应该是负值,否则斜率应该是正值,以此表征用户使用情况的变化趋势。5.7各种使用频次的变化情况
6.只对高中价值客户进行流失预测,低价值的客户就不管了
7. 可能的解决方案 Pareto/NBD模型
8. 要解决的问题 时间周期,怎么预测高价值用户的定义
直接使用RFM模型就可了
https://mp.weixin.qq.com/s/zpkWi1HZ94skqW_st0sY-w
数据分析|如何做好用户流失预警?
重点
https://mp.weixin.qq.com/s/3_jXRqn8cgLg6lymX_ijcA
总算是把用户流失分析讲清楚了! 重点 如何界定流失
如何合理的定义用户流失
https://blog.csdn.net/xzx1232010/article/details/90257169
重点
https://zhuanlan.zhihu.com/p/83703833
我们聊用户流失,首先要搞清楚的是“什么样的用户行为才算是流失”
这个问题,看似很难回答,不过只要抓住两个关键点,就能从容破题。
一是“动作”,二是“时间范围”。
可能是登录,可能是使用时长,在电商行业更关注的是购买。
量化的核心逻辑,是挖掘出不同时间范围用户,在此后一段时间的回购率分布。
用户下载注册一个产品是带着需求来的,是想解决自己的问题的。但是这个需求可能有所不同,有可能只是用户的一个普通需求,也有可能是个刚性需求,还有可能是个痛点需求。举例来说,最近太累,想去马尔代夫放松一下,这是个普通需求,到了马尔代夫玩了半天有点饿了,想吃东西了,这个是刚性需求,于是上网看了一下推荐,刚好附近有家餐厅,但是评价不好而且很贵,有家味道很好的但是离得又很远,找一个离得近、味道不错而且又实惠的餐厅就是个痛点需求。
所以,普通需求→刚需→痛点是一个逐层递进的过程,逐层体现用户希望解决问题的迫切程度,所以如果产品可以解决刚需就不要满足于仅解决普通需求,如果可以解决用户痛点就不要仅停留在解决刚需问题,用户越迫切,产品价值就更容易得以体现,用户的粘性自然就会更强,流失的概率也会小很多。
这些动作貌似无法处理
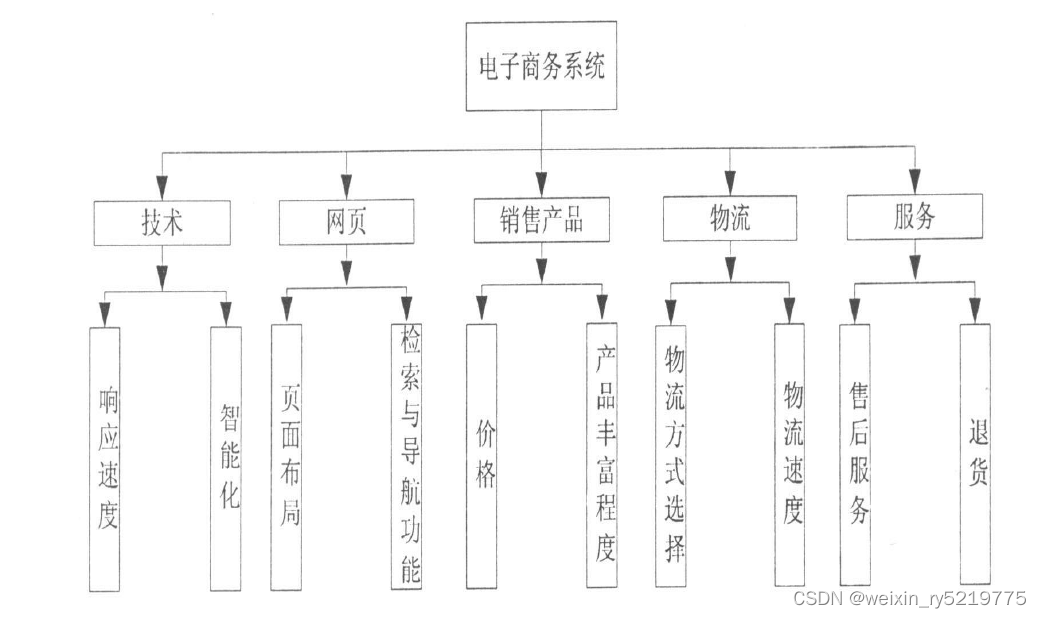
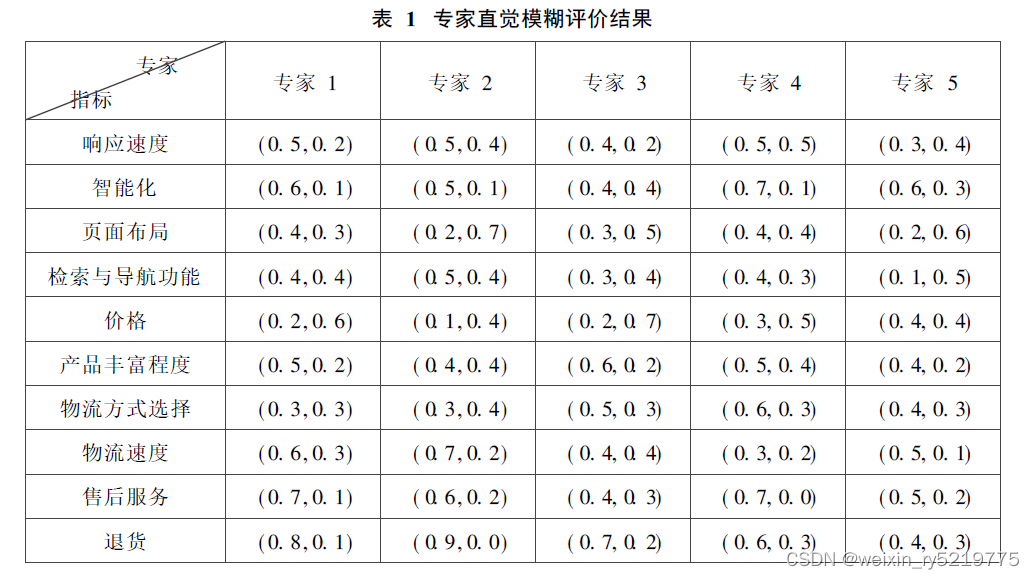
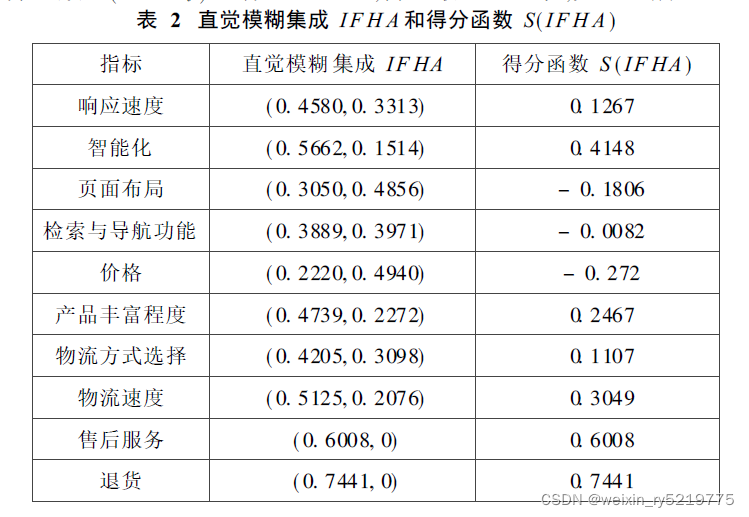
B2C电子商务客户流失原因评估研究.pdf
主观原因主要包括商业银行产品单一、服务系统有问题、产品缺乏创新、
员工跳槽、对客户投诉处理不及时、客户遭遇其他银行新的诱惑、客户欣赏和需求标准发生变化等。
( 三) 客户流失特征分析
商业银行客户流失的特征最为突出的有两类:
渐进型( 间接提示型) 流失和中断型流失。渐进型流
失主要表现为客户近期交易品种、交易次数、交易
金额和存贷款余额逐步减少。中断型流失主要表现
为睡眠型流失和突然中断型流失。睡眠型流失是指
账户依然存在, 但交易已经停止; 突然中断型流失
是指客户流失前正常交易, 由于某种原因, 突然中
断了交易, 并直接结清了账户。
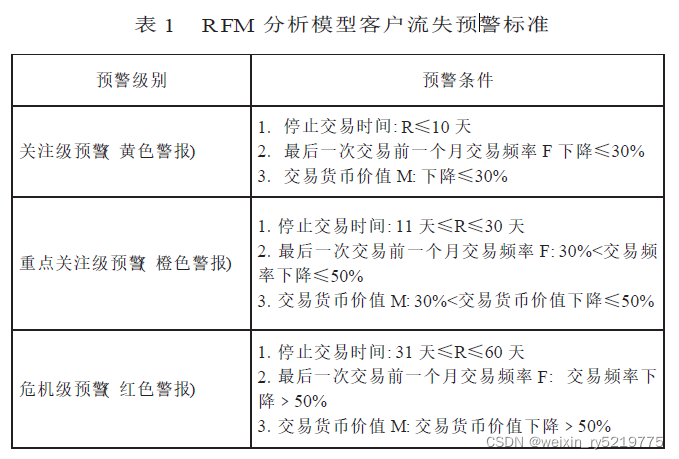
( 五) 客户流失预警分析
客户流失预警分析分为单一客户流失预警分
析、客户群流失分析两类。单一客户流失预警分析
采取RFM模型, 主要是对商业银行客户最近一次
交易的时间距当今有多远、频率、货币价值指标进
行分析, 设定一个参数值, 由系统自动报警。客户群
流失分析, 主要是对商业银行客户流失率设定一个
预警参数, 当某一客户群客户流失率达到所设定的
预警值时, 由系统自动报警。
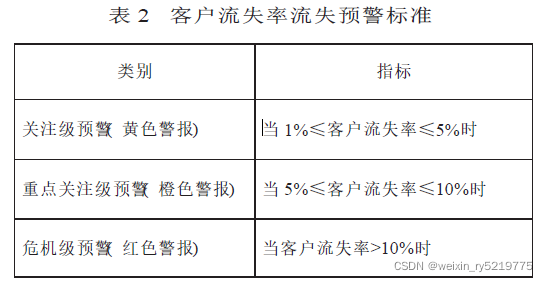
表1 RFM 分析模型客户流失预警标准
- 客户群流失预警
目标变量的选
择: 在客户流失分析系统中, 实际面对的流失主要
有账户取消发生的流失和账户休眠发生的流失两
种形式。对于不同的流失形式, 我们需要
选取不同的目标变量。
静态数据和动态数据。
静态数据指的是不会经常改变的数据, 包
括客户的基本信息。动态数据指的是经常
或定期改变的数据, 如每月存取记录、消
费金额、消费特征等
浅谈商业银行的客户流失.pdf 重点
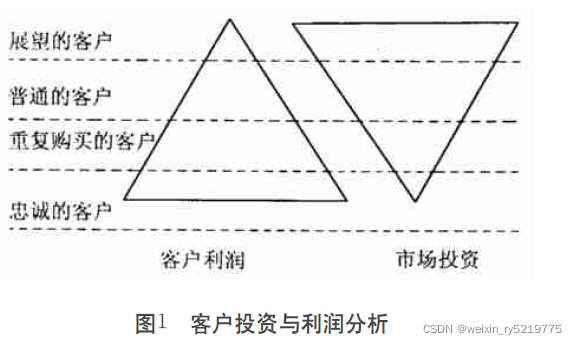
客户流失预测整个流程可以参考这个文档
客户价值矩阵分类客户
BtoC电子商务中客户流失的分析.pdf
https://www.doc88.com/p-9109492724714.html?r=1
高价值客户
https://mp.weixin.qq.com/s/4gDRtxILfAbLMb1UMJJ6Yw
如何搭建客户流失预警?
结果表明,不同类型客户流失因素的影响强度不同。对活跃用户而言,客户购买总金额是影响客户流失的主要因素;对非活跃用户而言,客户进入店铺的时间越长越可能留住客户。
一般传统线下的客户关系主要靠契约维持,而电子商务中的客户关系属于非契约关系
目前,客户流失研究主要集中于电信、金融等
行业,而电子商务作为互联网快速发展所衍生的行业,
也受到了学者们的青睐。
考虑电子商务客户冲动购买心理及进入商家的时
间长度,结合学者对客户价值的研究,除RFM 模型中
频率(F)、时间间隔(R)、金钱(M)指标外,还引
进了客户购买的最大金额(MM)、进入店铺的时间长度
(L)、购买天数(D)以及购买的概率(G)。其中,进入店铺
的时间长度指客户在观察期内第一次消费的时间距离
客户最后消费时间的长度,概率是指客户在已消费的天
数中平均每天购买的次数。
时间间隔(R):客户在观察期间第一次消费的时
间距离观察期最后一次消费时间长度(流失期限中);
频率(F):客户在单位时间上购买的次数;
金钱(M):客户在观察期消费的总金额;
最大金额(MM):客户在观察期消费的最大金额;
进入店铺的时间长度(L):客户在观察期后第一次
消费时间距离客户最后消费的时间长度;
购买天数(D):客户在观察期总消费天数;
概率(G):客户在观察期内消费的天数中平均每天
购买的次数。
本文主要运用拐点理论确定流失期限,利用客户购
买天数确定个体的活跃度阈值,将其分为活跃与非活跃
用户两类。
电子商务的客户消费习惯存在着周期性,当客户首次消费之后,
存在着一段时间的无消费周期,但在未来的某一时间若
还会出现消费行为,则代表客户回购,若未出现消费行
为,则代表客户没有回购,客户彻底流失,其中首次购
买后无消费的周期则为流失期限,具体见公式(8) 重点

客户流失期限的长度与客户的回购率成反比,本文
设定了不同时期的流失期限长度进行客户回购率的统
计,并观察客户回购率随客户流失期限的增大时的收敛
速度,本文以“月”为单位设定流失期限,根据不同流
失期限回购率的变化曲线,使用拐点理论进行流失期限
的设定,如图6 所示。
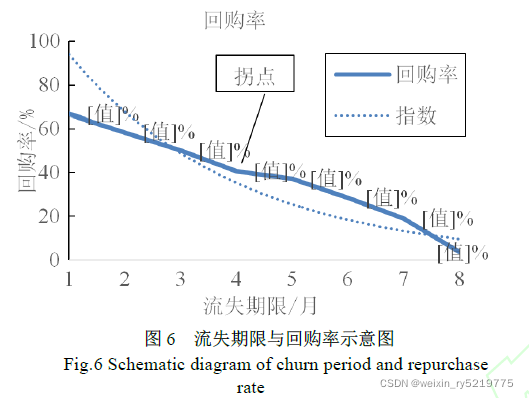
拐点理论是指X 轴上的数值增大时Y 轴上的数值
随之变化,直到到达某个点时,Y 轴变化的程度明显减
少,则称为“拐点”
拐点理论是指X 轴上的数值增大时Y 轴上的数值
随之变化,直到到达某个点时,Y 轴变化的程度明显减
少,则称为“拐点”。由图所知,随着流失期限增大,
用户回购率一直降低。当流失期限为4 个月时,回购率
降低幅度明显减小。因此,设置4 为拐点。
根据拐点理论知,客户流失期限为4 个月,具体表
现在2010 年12 月至2011 年3 月之间有过购买行为,
且连续4 个月间未发生购买行为的客户,称之为客户流
失。
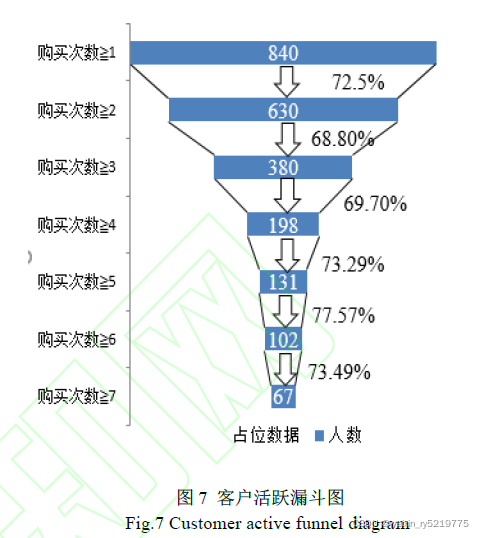
客户活跃漏斗图
客户活跃阈值确定
选取2010 年12 月到2011 年3 月份的所有客户的
数据,统计这4 个月中消费者消费的天数,绘制漏斗图,
运用客户购买的天数这个属性加以漏斗图与其转
化率可以解决客户是否活跃的问题。如图所示,购买天
数大于等于3 天的时候,转换率大于50%,且与购买天
数大于等于4 天的转换率差别不大,所以确定活跃的购
买天数为3 天及以上,将数据分为了活跃与非活跃两大
类,活跃用户为购买天数大于等于3 天的客户群体,非
活跃用户为购买天数小于3 天的客户,将数据集划分成
活跃用户群体380 位,非活跃客户用户460 位。
电子商务客户流失的DBN预测模型研究网络首发.pdf 重点
特征
组合预测的一种实现方式
电子商务客户流失的建模与预测研究.pdf
1994 年提出了著名的SMC模
型[ 3 -4]
, 通过预测客户的活跃程度, 较好地解决了
客户流失预测问题, 被誉为“首个真正意义上的客
户行为预测模型”[
SMC模型在总体层次和典型客户上对
客户流失预测是有效的, 但在个体层次上预测效
果还不够理想, 有大量客户无法区分出其活跃度
的差异
电子商务客户流失三阶段预测模型.pdf

流失原因

挽留手段
高价值客户流失预警及挽留策略分析.pdf
针对电信运营商的老客户保留问题,
通过对客户流失原因的分析,将客户区分并给出
不同的流失标准,分别用C5. 0 决策树、支持向量
机、C&T 决策树、logistic 回归和神经网络分别建
模预测,并最终通过增加一个置信区间的方法提
出融合模型,降低了预测风险
证券客户特征
2. 因变量的假设及获得。模型假设: 因为客
户流失状态数据是证券公司的商业机密,无法获
得。因此,本文在实证部分假设各项指标表现
“较激进”的客户为流失客户,交易活跃度低,投
资能力差,流失风险高,即对证券公司的贡献小,
Y 值取为1; 各项指标表现“较稳健”的客户为正
常投资客户,交易活跃度高,投资能力好,流失风
险低,即对证券公司的贡献大,Y 值取为0。
聚类做流失和非流失客户的划分
基于logistic模型的证券公司客户流失预警分析.pdf
完整分析过程流程 重点
框架
加权的聚类算法
k-means 算法存在一定的缺陷,即进行聚类时,
针对的是全部属性,而且对这些属性采用相同的重
要性进行处理,但是在很大程度上,不同的属性对距
离的影响是不同的,需要分别对待。否则对相似性
计算的时候,可能产生误导,这种误导被称之为“维
数陷阱”。为了解决这一问题,本文提出一种改进的
聚类算法-加权的聚类算法,即为数据库中的每一属
性增加一个权值参数,让不同的数据库属性进行聚
类时产生不同的效果,从而不同程度上影响距离的
产生。从欧氏空间角度分析,将相关属性所对应的
轴拉长,而将属性无关所对应的轴缩短。
通过直接考察自变量和因变量的差异的大小来给每个自变量不同的权重
越相同则权重越大

聚类数目
客户分割矩阵找出高价值客户
根据客户价值和客户流失风险,他把客户分成
了四类:
1)需求客户:具有较高价值但流失风险高的客
户,这类客户属于最关键的客户群体;
2)企业客户:客户价值高且流失风险低的客户;
3)价格敏感客户:客户价值低且流失风险高的
客户;
4)潜力客户:客户价值低且流失风险也低的客户。
预测客户流失模型的好坏的评估指标是覆盖率
和准确率,其中,覆盖率是指正确预测的流失客户数
占实际流失客户的比例,而准确率是指预测为流失
客户中实际流失客户所占的比例。定义混淆矩阵如
下表3所示。
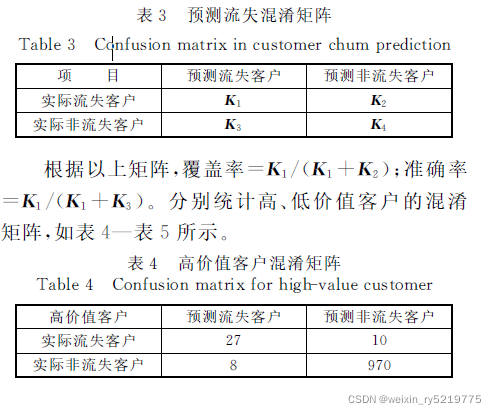
流失混淆矩阵
基于改进聚类的电信客户流失预测分析 重点
客户流失是指客户终止或者显著减少使用企业提供的产品或服务, 而转向了其他企业H
按照客户自身意愿, 客户流失可分为两类—类是被动流失, 即企业放弃了具有拖欠、欺诈
或低利润等特征的客户; 另一类则是主动流失, 即客户由于自身原因(如地点变更) 或企业原
因(如产品价格升高) 主动终止了与企业的关系.
目前, 国内外分析客户流
失原因的研究不多, 实证研究甚少, 且基本集中在电信、金融、电子商务三个行业
采用基于统计学的一般模型, 分析客户每次
购买的时间间隔, 进而预测客户流失率, 揭示保健医药行业客户流失的一般规律. 其次, 从企
业产品的角度出发, 通过分析客户购买的产品种类、数量以及购买间隔等指标, 计算每种产
品的客户流失概率, 不仅找出导致客户流失的主要产品和最吸引客户的产品, 还分析这些产
品的共同点和差异性, 为企业生产、销售产品提供有效的战略指导
目前, 保健药品企业主要拥有以下三大部分的信息: 交易数据信息、产品特信息、顾
客的个人特征信息( 人口统计学指标) . 这
研究框架

流失概率和忠诚概率的关系

流失客户定义
直接通过购买间隔的整体分布概率来估计
基于海量交易数据的保健药品客户流失规律及预测研究.pdf 重点

SMC模型的适用范围
电子商务客户流失预测问题具有特殊性, 电子商务网站中的顾客属于典型的非契约型客户, 其购买行
为是随机的过程, 并且受地域经济、市场、个体背景、文化等多因素影响采用单一的概率模型处理这类流
失预测间题, 在总体层次和典型客户上是有效的, 但在个体层次上预测效果不佳有学者提出把概率建模仅依
赖少数关键变量的鲁棒性和数据挖掘擅长处理众多解释变量的能力结合起来应用到电子商务领域, 并取得了
一定的成果“一’ 但是这些方法未考虑国内电子商务顾客的消费行为有着明显的地域性, 在不同地区具有
不同活跃度的客户, 实际上未来的活跃程度可能是类似的其次, 电子商务客户流失相关数据是海量的, 且解
释变量是高维的, 上述方法采用的概率模型活跃度闭值设定困难, 参数估计比较复杂, 效率有待提高最后,
未考虑客户流失数据的非平衡住, 电子商务客户流失预测是属于类别严重不对称的分类问题, 即流失客户数
量远高于不流失客户数量, 且对流失客户的误判损失远大于对非流失客户的误判损失因此, 本文建立启发
式算法与支持向量机融合的电子商务客户流失预测模型, 拓展了模型活跃度计算的推导思路,
并结合实际电子商务情境提出了一种融入地域因素的启发式算法在粗糙集理论基础上提出了一种改进的高
效属性约简粗糙集方法最后以融入客户活跃度的非平衡支持向量机算法实现整个模型的构建, 意图解决上
述问题
之前的流失预测问题
利用统计模型计算出活跃度
融入个体活跃度的电子商务客户流失预测模型.pdf

特征
神经网络在我国电商企业客户流失风险预测中的应用研究.pdf